|
💡
|
Vous êtes en train de lire le Chapitre 7 du livre “Node.js”, écrit par Thomas Parisot et publié aux Éditions Eyrolles. L’ouvrage vous plaît ? Achetez-le sur Amazon.fr ou en librairie. Donnez quelques euros pour contribuer à sa gratuité en ligne. |
Nous allons apprendre à composer et à tester une application web créée de toutes pièces ou avec l’aide du framework Express.
-
Composer son application web
-
Organiser une application avec le framework Express
-
Vers un code réutilisable et testable
-
Pour aller plus loin
Le modèle d’application web de Node se rapproche de celui de Ruby et diffère de l’univers PHP.
Nous allons mieux comprendre le mécanisme de requête et de réponse HTTP en créant une application web module par module, fonctionnalité par fonctionnalité.
Dans un second temps, nous organiserons notre code avec le framework Express. Nous verrons en quoi notre application gagne en clarté, comment générer du HTML de façon dynamique avec des informations issues d’une base de données.
Nous consoliderons notre savoir en organisant notre code de sorte à le rendre plus résilient et testable – chose que nous apprendrons à faire pas à pas.
|
💬
|
Remarque Versions de Node et npm
Le contenu de ce chapitre utilise les versions Node v10 et npm v6. Ce sont les versions stables recommandées en 2022. |
Une application web est une construction applicative qui est à l’écoute de connexions réseau initiées par un client – un navigateur, un automate, etc. Elle est structurée autour de la lecture d’une requête entrante (lecture) et de l’émission d’une réponse sortante (écriture). Chaque requête porte en elle une intention (un chemin d’accès, une préférence de format, des éléments d’identification) et implique une réponse en retour (des données et des éléments pour les contextualiser).
L’ingénierie d’une application web consiste à comprendre les requêtes entrantes et à construire une réponse appropriée à chaque fois, le plus rapidement possible.
Ce chapitre s’inscrit dans la continuité de la découverte du
module http
(chapitre 4).
|
💬
|
Documentation En-têtes HTTP
Ce chapitre fait souvent référence à des en-têtes HTTP. La documentation MDN web docs les liste tous, avec le détail de leurs valeurs possibles : C’est un onglet intéressant à ouvrir en parallèle de cette lecture – je l’ai ouvert en permanence pour écrire ce chapitre. |
8. Composer son application web
Dans cette première section, nous allons nous focaliser sur la construction d’une application web avec une approche modulaire. Nous partirons du concept de requête et de réponse. Petit à petit, nous allons greffer des modules pour comprendre et donner du sens à leurs contenus respectifs.
Le protocole HTTP est le dialecte informatique utilisé et compris pour exprimer les requêtes (émises par un client) et les réponses (émises par un serveur). Les navigateurs web sont des clients tandis que notre application Node est un serveur.
Le logiciel curl (curl.haxx.se) est un client en ligne de commandes. Il est souvent installé par défaut sur les distributions Linux, sur macOS et à partir de Windows 7 – via le terminal PowerShell.
Utilisons curl pour observer le contenu d’une requête et de sa réponse.
curl -v http://perdu.com GET / HTTP/1.1 Host: perdu.com User-Agent: curl/7.54.0 Accept: */*
-
Exécution de la requête.
-
Expression de la méthode, du chemin d’accès demandé et du protocole de discussion employé – ici, HTTP dans sa version
1.1. -
En-tête de requête.
Un en-tête est exprimé sous la forme Clé: Valeur.
Chacun précise un élément de contexte.
Certains influencent plus que d’autres la réponse du serveur, si
celui-ci les comprend.
Voyons maintenant la réponse :
HTTP/1.1 200 OK Date: Thu, 28 Jun 2018 19:02:27 GMT Server: Apache Last-Modified: Thu, 02 Jun 2016 06:01:08 GMT ETag: "cc-5344555136fe9" Accept-Ranges: bytes Content-Length: 204 Vary: Accept-Encoding Content-Type: text/html <html><head><title>Vous Etes Perdu ?</title> …</html>
-
Expression du statut de la réponse avec un code numérique et une version intelligible.
-
En-tête de réponse.
-
En-tête de réponse – celle-ci indique au client comment interpréter le corps du message.
-
Corps du message.
La réponse dispose elle aussi d’en-têtes. Cette fois, ils guident le client dans son interprétation du résultat. Le corps du message est séparé par une ligne vide. C’est la partie visible de la réponse dans un navigateur web, le contenu qui s’affiche sous nos yeux.
Dans la prochaine section, nous visualiserons ces mêmes informations à partir d’un serveur HTTP que nous allons créer par nous-même. Nous retracerons plus en détail l’odyssée d’une requête HTTP dans la section “Comprendre le modèle HTTP”, en fin de chapitre.
|
💡
|
Pratique Jouer avec les exemples dans un terminal
Les exemples titrés d’un nom de fichier peuvent être installés sur votre ordinateur. Exécutez-les dans un terminal et amusez-vous à les modifier en parallèle de votre lecture pour voir ce qui change. Installation des exemples via le module npm
nodebooknpm install --global nodebook nodebook install chapter-07 cd $(nodebook dir chapter-07) La commande suivante devrait afficher un résultat qui confirme que vous êtes au bon endroit : node hello.js Suivez à nouveau les instructions d’installation pour rétablir les exemples dans leur état initial. |
8.1. Démarrer un serveur HTTP
Nous l’avons dit : une requête HTTP envoyée vers un hôte reçoit une réponse. Cet hôte doit au préalable avoir installé et démarré un serveur HTTP qui écoute ces demandes.
Le script d’exemple server/start.js répond à ce besoin.
Une fois démarré, il est joignable à l’adresse localhost:4000.
Il affichera alors les en-têtes des requêtes et de leurs réponses :
node server/start.js
'use strict';
const {createServer} = require('http');
const server = createServer();
server.on('request', (request, response) => {
response.setHeader('Content-Type', 'text/html'); // (1)
response.end('<h1>Hello World</h1>');
console.log(request.headers); // (2)
console.log(response.getHeaders()); // (3)
});
server.listen(4000);-
Comme nous retournons du HTML au client, nous explicitons le type de contenu de la réponse.
-
Affiche les en-têtes de la requête reçue par le serveur – le contenu varie selon le client utilisé.
-
Affiche les en-têtes de la réponse – en l’occurrence
{ 'content-type': 'text/html' }.
Nous avons composé les fondations minimales pour créer une application web en mesure d’accepter des requêtes et de répondre quelque chose d’arbitraire certes mais compréhensible par un navigateur web.
Pourquoi avoir démarré le serveur sur le port 4000 dans l’exemple précédent ? C’est un choix arbitraire de ma part : nous pouvons démarrer un serveur HTTP sur n’importe quel port tant qu’il est libre et supérieur ou égal à 1000. Quand on cherche à se connecter à une adresse comme localhost (HTTP) et localhost (HTTPS), la valeur du port vaut implicitement 80 et 443, respectivement.
Le module npm get-port (npmjs.com/get-port) retourne
un numéro de port parmi ceux disponibles sur le système d’exploitation.
node server/port.js http://localhost:51765
'use strict';
const {createServer} = require('http');
const getPort = require('get-port');
const server = createServer();
getPort({ port: 4000 }).then(port => { // (1)
console.log(`http://localhost:${port}`); // (2)
server.listen(port); // (3)
});-
Exprime une préférence pour retourner le port 4000 s’il est disponible.
-
Affiche
localhost:4000si le port est disponible ; sinon, un autre nombre. -
Le serveur se met à l’écoute sur ce port.
Pour vous en rendre compte, démarrez le script server/start.js pour utiliser
le port 4000 et démarrez ensuite server/port.js.
|
💬
|
Performance Programme de longue durée
Une application web est un programme qui tourne en continu, pendant des heures et des journées entières. Chaque requête entrante occupe 1 Ko de mémoire – davantage si nous recevons des données de formulaire ou une pièce jointe. Une application web peut en recevoir plusieurs centaines à plusieurs milliers par seconde, selon la popularité du service. |
8.2. Répondre à un chemin (routing)
Nous avons vu qu’une URL est un identifiant qui se décompose en plusieurs
parties grâce au module url
(chapitre 4).
Une d’elles est le chemin d’accès à une ressource.
Par exemple, le chemin de l’URL localhost:4000/coucou est /coucou.
node path/request-url.js
'use strict';
const {createServer} = require('http');
const server = createServer().listen(4000);
server.on('request', (request, response) => {
if (request.url === '/') { // (1)
response.end('<a href="/hello">clique-moi</a>');
}
else if (request.url === '/coucou') { // (2)
response.end('<a href="/">coucou !</a>');
}
});-
Affiche un message spécifique au chemin
/. -
Affiche un autre message spécifique au chemin
/coucou.
Les deux seules ressources mises à disposition sur localhost:4000
sont accessibles avec les chemins / et /coucou.
Aucun autre chemin n’aboutira.
C’est d’ailleurs un problème puisque, en réalité, nous n’envoyons pas de réponse pour un chemin inconnu. Et c’est à nous de gérer ce cas de figure :
node path/404.js
'use strict';
const {createServer} = require('http');
const server = createServer().listen(4000);
server.on('request', (request, response) => {
if (request.url === '/') { // (1)
response.end('<a href="/hello">clique-moi</a>');
}
else {
response.statusCode = 404; // (2)
response.end('<h1>Page introuvable</h1>'); // (3)
}
});-
Seul le chemin
/est disponible dans l’application. -
Le code HTTP de la réponse est réglé sur
404. -
Une requête vers une page introuvable peut quand même recevoir du contenu.
La prise en compte d’une ressource inconnue de notre application fait émerger
un nouveau concept : le statut de la réponse.
Ce statut est un code numérique qui donne des indications sur la ressource retournée.
Dans ce cas de figure, le statut 404 de la réponse indique au client de
ne pas considérer le contenu comme celui qui était demandé.
Par défaut et sauf mention contraire, le statut est 200.
| Code | Raison | Explication |
|---|---|---|
|
|
La ressource demandée est retournée en réponse. |
|
|
La ressource demandée a été déplacée. |
|
|
La ressource n’a pas été modifiée depuis la dernière fois. |
|
|
La requête est incomplète ou incompréhensible par le serveur. |
|
|
La ressource n’est accessible que sur preuve d’identification. |
|
|
L’accès à la ressource est interdit. |
|
|
La ressource n’existe pas. |
|
|
Le serveur distant est en erreur. |
Les statuts HTTP sont importants dans la création d’applications web.
Leur code permet de vérifier que le client et le serveur se sont bien compris.
Si une page d’erreur est affichée avec un statut 200, le client sera dans
l’impossibilité de deviner qu’il ne s’agit pas du contenu attendu.
| Code | Raison | Explication |
|---|---|---|
|
|
Le serveur indique basculer vers le protocole spécifié dans l’en-tête |
|
|
La ressource demandée a été créée. |
|
|
La demande a été acceptée et la ressource sera disponible ultérieurement. |
|
|
La ressource demandée n’a pas de contenu. |
|
|
La ressource demandée est temporairement disponible à une autre adresse. |
|
|
Le serveur distant répond qu’il n’est pas disponible pour l’instant. |
Une application web devient vite compliquée à gérer si nous devons lister
tous les chemins possibles.
C’est à ce moment qu’entre en jeu le routing, une technique pour décrire
des chemins d’accès au lieu de s’embourber dans une longue liste de if … else.
Nous utilisons le module npm find-my-way (npmjs.com/find-my-way)
pour transformer l’exemple path/request-url.js
en quelque chose de plus modulaire :
node path/routes.js
'use strict';
const {createServer} = require('http');
const router = require('find-my-way')(); // (1)
router.get('/', (request, response) => { // (2)
response.end('<a href="/coucou">clique-moi</a>');
});
router.get('/coucou', (request, response) => { // (3)
response.end('<a href="/">retour</a>');
});
const server = createServer().listen(4000)
.on('request', (req, res) => router.lookup(req, res));// (4)-
Création de la table de routage.
-
Définition de la réponse du chemin d’accès
/. -
Définition de la réponse du chemin d’accès
/coucou. -
Intégration du routeur aux requêtes entrantes du serveur HTTP.
Les routeurs commencent à vraiment nous faire gagner du temps lorsqu’il s’agit d’extraire des informations utiles depuis le chemin et de les gérer dynamiquement :
node path/route-params.js
'use strict';
const {createServer} = require('http');
const router = require('find-my-way')();
router.get('/hello/:word', (req, response, params) => { // (1)
response.end(`<p>hello ${params.word}</p>`); // (2)
});
const server = createServer().listen(4000)
.on('request', (req, res) => router.lookup(req, res));-
Création d’une route paramétrée – le symbole
:wordest accessible dans le troisième argument, en tant queparams.word. -
Affiche une phrase composée avec le paramètre de notre route.
Dirigez-vous vers localhost:4000/hello/word pour voir le résultat s’afficher. Changez le dernier segment du chemin pour observer le changement.
Ce mécanisme est utile pour relier un identifiant à un enregistrement précis en base de données, par exemple. Il se complète avec les arguments d’URL pour véhiculer des éléments optionnels – nous y reviendrons plus loin.
|
⚠️
|
Sécurité Filtrer les données entrantes
C’est le moment de rappeler que toute information saisie par l’utilisateur
doit être filtrée et nettoyée avant d’être utilisée.
L’exemple Nous verrons tous ces aspects plus en détail dans la section “Protéger l’application”. |
Enfin, les routeurs contextualisent les actions à effectuer vis-à-vis d’une ressource grâce au verbe HTTP. Ce dernier communique une intention – récupération, mise à jour, suppression. Le routeur organise notre code pour déclencher une action adaptée à la méthode employée :
node path/method.js
'use strict';
const {createServer} = require('http');
const router = require('find-my-way')();
router.get('/', (request, response) => { // (1)
response.end('Bienvenue');
});
router.head('/', (request, response) => { // (2)
response.writeHead(200, { // (3)
'X-Jobs': 'https://jobs.humancoders.com' // (4)
});
response.end('Invisible'); // (5)
});
const server = createServer().listen(4000)
.on('request', (req, res) => router.lookup(req, res));-
Définition du chemin d’accès
/– verbeGET(récupération). -
Définition du chemin d’accès
/– verbeHEADcette fois. -
La méthode
response.writeHeadest un moyen de définir le statut en même temps que les en-têtes de réponse. -
Définition d’un en-tête personnalisé – le préfixe
X-indique qu’il n’est pas lié au standard HTTP. -
Écriture du corps du message – nous verrons qu’il est ignoré et n’est pas transmis au client.
Les navigateurs web affichent seulement notre route GET car c’est
leur fonctionnement par défaut.
Ils comprennent le verbe POST pour téléverser des fichiers ou
transmettre des formulaires.
Tournons-nous à nouveau vers le programme curl pour observer les différences
entre les réponses nos deux verbes HTTP GET et HEAD :
curl http://localhost:4000 Bienvenue curl --head http://localhost:4000 HTTP/1.1 200 OK X-Jobs: https://jobs.humancoders.com Date: Sun, 01 Jul 2018 15:43:56 GMT Connection: keep-alive
L’utilisation de HEAD renvoie uniquement les en-têtes de réponse et nous
économise la génération d’un gabarit.
D’un point de vue client, le verbe HEAD aide à inspecter des ressources
sans avoir à télécharger le contenu – ce sont autant de kilo ou mégaoctets
économisés.
| Verbe | Description |
|---|---|
|
Récupération d’une ressource. |
|
Récupération d’une ressource – seulement les en-têtes. |
|
Création d’une ressource. |
|
Mise à jour d’une ressource. |
|
Mise à jour partielle d’une ressource. |
|
Demande de suppression d’une ressource. |
La responsabilité de comprendre ces verbes revient à notre application. C’est donc à nous de leur associer une action pour les prendre en charge.
8.3. Répondre avec des fichiers statiques
Les chemins d’accès s’associent aussi à des fichiers statiques. Ainsi, à une URL correspond un fichier placé sur notre disque dur. J’ai placé trois fichiers de différentes natures (texte, image, PDF) pour illustrer les exemples de cette section.
tree -a static/files static/files ├── .eslintrc.yaml ├── doc.pdf └── screenshot.jpg
Nous allons commencer par mettre à disposition un seul fichier, quel que soit le chemin demandé :
node static/stream.js
'use strict';
const {createServer} = require('http');
const {createReadStream} = require('fs');
const {join} = require('path');
const server = createServer().listen(4000);
server.on('request', (requet, response) => {
const filepath = join(__dirname, 'files', 'doc.pdf'); // (1)
createReadStream(filepath).pipe(response); // (2)
});-
Nous constituons un chemin d’accès avec
path.join()(chapitre 4, modulepath). -
Nous créons un flux de lecture vers ce fichier (chapitre 4, module
stream) et nous le redirigeons vers la réponse.
Ce que cet exemple nous apprend, c’est que l'objet de réponse est aussi un flux d’écriture. Peu importe le volume du fichier, l’envoi se régulera en fonction de la capacité de téléchargement du client et en consommant le minimum de mémoire possible. La lecture sera interrompue si le client annule le téléchargement.
Nous pouvons à présent étendre ce savoir nouvellement acquis en routant un chemin d’accès vers le répertoire qui contient nos fichiers.
node static/routes.js
'use strict';
const {createServer} = require('http');
const {createReadStream} = require('fs');
const {join} = require('path');
const router = require('find-my-way')();
const staticFiles = (request, response, params) => {
const filename = join(__dirname, 'files', params.file);// (2)
createReadStream(filename).pipe(response);
};
router.get('/files/:file', staticFiles); // (1)
router.head('/files/:file', staticFiles);
const server = createServer().listen(4000)
.on('request', (req, res) => router.lookup(req, res));-
Création d’une route paramétrée qui répond avec la fonction
staticFiles. -
Composition dynamique du chemin d’accès au fichier.
Si nous accédons à localhost:4000/files/doc.pdf et localhost:4000/files/screenshot.jpg, nous verrons les deux documents s’afficher dans notre navigateur. Il reste cependant un problème : l’accès à un chemin inconnu fait planter l’application.
{kind=link}
Nous constatons que notre approche est un peu trop naïve en regardant les en-têtes de réponse d’un peu plus près :
curl --head 'http://localhost:4000/files/doc.pdf' HTTP/1.1 200 OK Date: Mon, 02 Jul 2018 15:47:33 GMT Connection: keep-alive
-
C’est pour exécuter cette commande que j’ai ajouté l’écoute de la méthode
HEAD. En fait, nous gagnerions à documenter la ressource en transmettant des en-têtes supplémentaires. La question est : lesquels ?
|
⚠️
|
Sécurité Filtrer les données entrantes
Toute information saisie par l’utilisateur doit être filtrée et nettoyée avant
d’être utilisée.
L’exemple Nous verrons tous ces aspects plus en détail dans la section “Protéger l’application”. |
Nous allons nous baser sur le module npm send (npmjs.com/send)
pour améliorer l’exemple précédent et constater par nous-même quels
en-têtes sont utiles.
node static/send.js
'use strict';
const {createServer} = require('http');
const {join} = require('path');
const send = require('send');
const router = require('find-my-way')();
const staticFiles = (request, response, params) => {
const pathname = params['*']; // (2)
const filename = join(__dirname, 'files', pathname);
send(request, filename).pipe(response); // (3)
};
router.get('/files/*', staticFiles); // (1)
router.head('/files/*', staticFiles);
const server = createServer().listen(4000)
.on('request', (req, res) => router.lookup(req, res));-
En utilisant la syntaxe
*, le routeur accepte une arborescence de chemins –doc.pdftout commeun/long/chemin.pdf. -
L’arborescence se récupère avec un paramètre du même nom –
*. -
Le module send prend en charge la suite de la transmission.
Nous n’avons pas apporté de grands bouleversements, si ce n’est que les fichiers inexistants ne font plus planter l’application et que les en-têtes de réponses sont plus fournis qu’avant :
curl --head 'http://localhost:4000/files/doc.pdf' HTTP/1.1 200 OK Accept-Ranges: bytes Cache-Control: public, max-age=0 Last-Modified: Tue, 12 Jun 2018 08:02:40 GMT ETag: W/"10c5d-163f304b0d2" Content-Type: application/pdf Content-Length: 68701 Date: Mon, 02 Jul 2018 15:52:18 GMT Connection: keep-alive
Parmi les en-têtes les plus importants, nous trouvons Content-Type,
Content-Length et Last-Modified.
Ils aident le client à interpréter ou représenter le contenu de manière optimale,
à informer de la taille du contenu (utile à l’animation de la barre de
téléchargement du navigateur web) et à distinguer l’ancienneté du fichier.
| En-tête | Utilité |
|---|---|
|
Explicite la nature du contenu mis à disposition. |
|
Indique si le contenu doit être affiché dans le client ou téléchargé sous un nom particulier. |
|
Active ou désactive la mise en cache de ce fichier par le client. |
|
Indique la date de dernière modification du contenu. |
|
Indique la longueur (en octets) du contenu. |
|
Indique le mode de compression utilisé pour transmettre les données. |
|
Indique la possibilité ou non de reprendre un téléchargement ou d’en choisir un segment avec l’en-tête de requête |
|
💡
|
Performance Utiliser Apache ou nginx en production
Si Node s’en sort bien pour envoyer des fichiers vers le client, les serveurs web Apache et nginx sont encore plus performants à ce niveau. C’est quelque chose à considérer si votre application sert principalement des fichiers statiques. Lisez le chapitre 6 pour apprendre à configurer Node derrière un autre serveur web. |
8.4. Réagir aux arguments d’URL
Les arguments d’une URL servent à affiner le contexte d’affichage d’une ressource donnée. Ces options servent par exemple à paginer du contenu ou spécifier une dimension, un filtre d’affichage ou encore une expression de recherche. En clair, elles servent à influencer la représentation d’une ressource ou information.
Par défaut, les arguments sont représentés de manière textuelle avec
le chemin d’accès, dans l’attribut request.url :
node arguments/intro.js
'use strict';
const {createServer} = require('http');
const server = createServer().listen(4000);
server.on('request', (request, response) => {
response.end(request.url); // (1)
});-
La page demandée affiche l’attribut de requête
url.
Nous voyons s’afficher /test?cle=valeur&option en nous rendant à l’adresse
localhost:4000/test?cle=valeur&option.
Ce n’est pas utilisable en l’état.
Le module url
(chapitre 4) entre en jeu.
En plus de déstructurer une URL entière, il sait aussi décomposer les options
et les transformer en un objet utilisable côté Node :
node arguments/parse.js
'use strict';
const {createServer} = require('http');
const {parse} = require('url');
const server = createServer().listen(4000);
server.on('request', (request, response) => {
const {search, query} = parse(request.url, true); // (1)
response.write(`${search}\n\n`); // (2)
response.write(JSON.stringify(query)); // (3)
response.end();
});-
Le deuxième argument de la fonction
url.parse()décompose les arguments, disponibles dans l’attributqueryde l’objet retourné. -
L’attribut
searchcorrespond aux arguments, sous forme textuelle. -
L’attribut
queryest un objet – ici, transformé pour être affiché dans la page sous forme de texte.
Cette fois, nous voyons s’afficher {"cle": "valeur", "option": ""} dans notre
navigateur lorsque nous nous rendons sur localhost:4000/test?cle=valeur&option.
C’est tout ce qu’il nous fallait pour l’utiliser dans notre application.
node arguments/format.js
'use strict';
const {createServer} = require('http');
const {parse} = require('url');
const {format} = require('date-fns');
const server = createServer().listen(4000);
server.on('request', (request, response) => {
const {query} = parse(request.url, true);
const text = format(new Date(), 'YYYY-MM-DD');
if (query.format === 'svg') { // (1)
response.setHeader('Content-Type', 'text/html');// (2)
response.end(`<svg viewBox="0 0 200 100">
<text x="0" y="50">${text}</text>
</svg>`);
}
else {
response.end(text); // (3)
}
});-
Nous rentrons dans ce bloc en présence de l’argument d’URL
format=svg. -
L’en-tête
Content-Typefait que le contenu est interprété (et affiché) comme du HTML – en retirant cette ligne, le document sera alors téléchargé. -
Sinon, le reste du temps, nous affichons la date telle quelle, en tant que texte. Les deux URL localhost:4000/date?format=svg et localhost:4000/date font référence à une même ressource, mais l’affichage s’adapte au contexte.
| Argument | Représentation |
|---|---|
|
|
|
|
|
|
|
💡
|
Performance Module npm parseurl
Si vous êtes à la recherche de performance, le module |
8.5. Recevoir des données de formulaire (POST)
Lorsque nous ne précisons pas la méthode employée, les outils et logiciels
utilisent par défaut la méthode GET.
Elle est associée à une récupération de données sans transmettre autre chose
que des en-têtes et un chemin d’accès.
Il y a des cas où nous avons besoin d’envoyer des données, pour les stocker
ou pour demander à créer un enregistrement.
Dans ce cas, nous utilisons la méthode POST et nous transmettons les informations
d’une manière différente.
Le serveur suivant affichera deux choses à chaque requête reçue : l’en-tête
Content-Type et le corps du message transmis par la requête.
node post/server.js
La commande curl règle le nom et la valeur d’un champ de formulaire
avec l’option -d.
Nous pouvons ainsi transmettre des données avec la méthode POST à notre
serveur :
curl -XPOST -d 'fromage=cabécou' -d 'remember_me=1' \ http://localhost:4000
C’est vraiment l’équivalent d’un classique formulaire HTML.
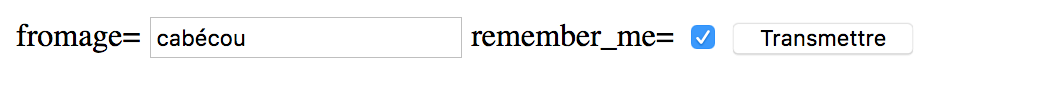
curl précédente<meta charset="utf-8">
<form action="http://localhost:4000" method="POST"> <!--(1)-->
<label>fromage=
<input name="fromage" type="text" value="cabécou">
</label>
<label>remember_me=
<input name="remember_me" type="checkbox" value="1" checked>
</label>
<button type="submit">Transmettre</button>
</form>-
Nous retrouvons l’indication de la méthode
POST.
Lorsque la page HTML est ouverte dans un navigateur et qu’on appuie sur le bouton
Transmettre, les mêmes informations qu’avec la commande curl s’affichent.
Il se trouve que Node aussi sait envoyer des informations de formulaire
avec le module http
(chapitre 4).
node post/send.js
'use strict';
const {stringify} = require('querystring');
const {request} = require('http');
const data = { fromage: 'cabécou', 'remember_me': 1 }; // (1)
const options = {
hostname: 'localhost',
port: 4000,
method: 'POST', // (2)
headers: {
'Content-Type': 'application/x-www-form-urlencoded'// (3)
}
};
request(options).end(stringify(data)); // (4)-
Création de la structure des données à transmettre.
-
Indication de la méthode
POST. -
Cet en-tête caractérise la manière d’organiser les données de formulaire – personnellement, je n’arrive jamais à retenir cette valeur et je la copie/colle toujours depuis Stack Overflow ou une documentation technique.
-
Les données sont sérialisées sous forme d’une chaîne de caractères, identique à ce que ferait un navigateur avec les données d’un formulaire.
Nous retrouvons l’en-tête Content-Type dans l’affichage du script post/server.js.
Le contenu du message envoyé ressemble beaucoup à des arguments d’URL
encodés avec encodeURIComponent().
post/server.jsapplication/x-www-form-urlencoded fromage=cab%C3%A9cou&remember_me=1
Comme dans les sections précédentes, nous devons décoder une chaîne de caractères pour en extraire sa signification et en faire quelque chose en ECMAScript.
Nous pourrions utiliser la fonction parse() du module Node querystring
pour décoder le contenu de cette chaîne, mais nous allons plutôt faire appel
au module npm co-body (npmjs.com/co-body).
Ce module décode plusieurs types de requêtes POST, illustrés dans d’autres
exemples de cette même section.
node post/server-parse.js
'use strict';
const {createServer} = require('http');
const parse = require('co-body');
const onRequest = (request, response) => {
parse(request) // (1)
.then(body => {
console.log(request.headers['content-type']);
console.log(body); // (2)
})
.catch(error => console.error(error.message)) // (3)
.finally(() => response.end());
};
createServer(onRequest).listen(4000);-
Le module co-body transforme une requête HTTP en un objet utilisable dans Node.
-
Le contenu de la variable ressemblera à quelque chose comme
{fromage: 'cabécou', remember_me: '1'}. -
Une erreur s’affichera en cas de problème pour décoder le corps de la requête entrante.
Il nous suffit d’exécuter à nouveau le script post/send.js pour observer
la différence et constater que nous pouvons désormais interpréter les données
d’un formulaire.
Le fichier post/send.js se simplifie si on utilise le module npm superagent
(npmjs.com/superagent).
Je le trouve simple d’utilisation et il fonctionne avec des promesses,
des formulaires et les téléversements de fichiers.
node post/send-data.js
'use strict';
const {post} = require('superagent');
post('http://localhost:4000') // (1)
.send('fromage=cabécou') // (2)
.send('remember_me=1')
.catch(error => console.log(error.message));-
URL de la ressource vers laquelle poster les informations.
-
La définition d’un champ de formulaire s’effectue à l’aide de la méthode
send()et d’une valeur ayant la forme d’une chaîne de caractères.
À ce stade-là, nous avons fait le nécessaire pour interpréter le contenu d’un formulaire sans pièce jointe. Notre serveur est même prêt à recevoir des données transmises en dehors d’un formulaire, au format JSON :
node post/send-json.js
'use strict';
const {post} = require('superagent');
post('http://localhost:4000')
.send({ // (1)
fromage: 'cabécou',
remember_me: 1
})
.catch(error => console.log(error.message));-
L’utilisation d’un objet ECMAScript suffit au module superagent pour transmettre les données au format JSON.
Nous constatons que la valeur de l’en-tête Content-Type change pour devenir
application/json.
Là aussi, le module co-body nous est utile, car il s’adapte au type des données
entrantes et les décode de manière transparente.
Il existe un dernier type d’encodage de données que nous pouvons nous attendre à recevoir. Ce sont les formulaires dits multipart.
node post/send-multipart.js
'use strict';
const {post} = require('superagent')
post('http://localhost:4000')
.field('fromage', 'cabécou') // (1)
.field('remember_me', 1)
.catch(error => console.log(error.message));-
Le module superagent utilise la méthode
field()pour définir la valeur d’un champ multipart.
Le serveur va pourtant afficher une erreur du type :
Unsupported content-type: multipart/form-data; boundary=--------------------------070345340228095473881249
Ce type d’encodage de données est plus complexe à gérer. Il va nous falloir passer à une autre stratégie, incontournable pour gérer le téléversement de fichiers.
8.6. Téléverser des fichiers
Le téléversement de fichier implique un peu plus de travail qu’un simple formulaire car la structure des données envoyées diffère mais aussi, surtout, parce que la réception et la gestion des fichiers demandent encore plus d’attention.
Voyons par nous-même à quoi ressemble une requête qui contient une pièce jointe.
node upload/server.js
'use strict';
const {createServer} = require('http');
const getStream = require('get-stream');
const onRequest = (request, response) => {
getStream(request).then(body => {
console.log(request.headers['content-type']);
console.log(body);
response.end();
});
};
createServer(onRequest).listen(4000);Ce serveur affiche le contenu d’une requête entrante.
La requête suivante illustre le téléversement d’un fichier avec le programme curl.
Notez que, cette fois-ci, nous utilisons l’option -F et que la valeur
est préfixée avec le caractère @, suivi du chemin d’accès au fichier en question.
curl -XPOST -F 'hello=@upload/hello.txt' \
http://localhost:4000
Cette commande est équivalente à l’envoi du formulaire HTML suivant :
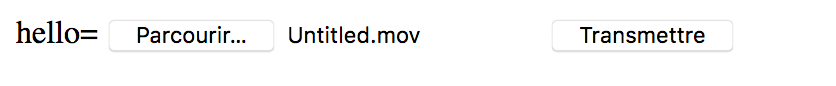
<meta charset="utf-8">
<form action="http://localhost:4000" method="POST"
enctype="multipart/form-data"> <!--(1)-->
<label>hello=
<input name="hello" type="file"> <!--(2)-->
</label>
<button type="submit">Transmettre</button>
</form>-
Nous retrouvons l’encodage
multipart/form-datadans l’attributenctype. -
Un fichier se téléverse avec un champ de type
file.
La structure du corps de message d’une requête multipart/form-data envoyée
avec la commande curl ou un formulaire HTML ressemble ce qui suit :
multipart/form-data; boundary=-----1acfa07ebbd71d3c -----1acfa07ebbd71d3c Content-Disposition: form-data; name="hello"; filename="hello.txt" Content-Type: text/plain Hello World -----1acfa07ebbd71d3c----
-
Contenu de l’en-tête
Content-Type– l’attributboundaryprécise le motif de délimitation des différents champs. -
Ouverture des informations du premier champ.
-
Les attributs
nameetfilenamedéfinissent respectivement le nom du champ de formulaire et celui du fichier en question. -
L’attribut
Content-Typeconcerne le fichier et aide à comprendre comment interpréter son contenu – ici, du texte brut. -
Fermeture des informations du premier champ.
|
💡
|
Pratique Courriels et pièces jointes
Les courriels utilisent aussi l’encodage |
Il nous faudrait écrire davantage que 20 lignes de code si nous devions nous-même interpréter un contenu de requête qui contient des pièces jointes. C’est suffisamment compliqué à programmer de manière robuste pour que le module co-body vu dans la section précédente ne s’en charge pas et recommande le module formidable (npmjs.com/formidable). C’est exactement ce que nous allons faire pour outiller un nouveau serveur.
node upload/server-parse.js
'use strict';
const {createServer} = require('http');
const formidable = require('formidable');
const onRequest = (request, response) => {
const form = new formidable.IncomingForm();
form.parse(request, (error, fields, files) => { // (1)
const testFile = files.hello; // (2)
console.log(testFile.type); // (3)
console.log(testFile.name); // (4)
console.log(testFile.size); // (5)
console.log(testFile.path); // (6)
response.end();
});
};
createServer(onRequest).listen(4000);-
Le module formidable différencie les données et les fichiers.
-
Nous accédons aux informations d’un fichier au travers d’une clé, identique à celle de son champ
namedans le formulaire. -
Affiche
text/plain– la valeur duContent-Typedu fichier. -
Affiche
hello.txt– c’est le nom du fichier tel qu’il était nommé sur le poste client. -
Affiche
12– c’est le poids total du fichier. -
Affiche un chemin d’accès vers l’emplacement de stockage temporaire du fichier téléversé.
Nous sommes en mesure de recevoir des pièces jointes depuis un formulaire.
Le module fs (chapitre 4)
propose le nécessaire pour déplacer le fichier ailleurs sur le système ou
pour en lire le contenu et le stocker ailleurs – sur un service de stockage distant
(Amazon S3, par exemple).
|
⚠️
|
Sécurité Un fichier texte n’a de texte que le nom
Comme pour toute donnée transmise par un utilisateur ou une utilisatrice, nous devons rester vigilant·e sur le contenu des fichiers pour éviter des attaques mal intentionnées. Un fichier texte qui contient du JavaScript pourrait être exécuté comme un script sur le poste client et ainsi servir à subtiliser des données privées ou aider quelqu’un à usurper une identité sur le service. |
Je recommande deux approches à appliquer avant même de faire quoi que ce soit avec une pièce jointe fraîchement téléversée :
-
S’il s’agit d’un fichier texte : filtrer le contenu du fichier en retirant tout ce qui ressemble à du code arbitraire et filtrer le contenu à l’affichage pour retirer tout balisage HTML (voir section “Protéger son application”).
-
S’il s’agit d’un fichier binaire (image, vidéo, PDF) : utiliser un antivirus en ligne de commande pour scanner le contenu – ClamAV (www.clamav.net) est un excellent antivirus open source.
Ces opérations risquent de prendre du temps – de quelques secondes à plusieurs minutes dans le cas de fichiers volumineux. Au lieu de faire attendre l’utilisateur devant son écran, je recommande de faire appel à un mécanisme de file d’attente pour traiter l’effort indépendamment, en fonction des capacités de calcul disponibles.
Enfin, quand vous avez fini d’utiliser la pièce jointe – ou si vous ne l’utilisez pas – pensez aussi à la supprimer du répertoire temporaire. Le disque dur du serveur pourrait manquer d’espace si plusieurs fichiers volumineux étaient déposés en peu de temps.
8.7. Garder un lien avec les cookies
Un cookie est une information partagée entre un client et un serveur pour
une durée limitée dans le temps.
Le client transmet les cookies au serveur afin que ce dernier contextualise
la demande – un identifiant utilisateur, des préférences ou autre.
Un cookie créé par le domaine example.com est envoyé seulement lors d’une
visite à example.com – sous-domaines inclus.
Ce mécanisme est aujourd’hui tristement célèbre pour son détournement par les industries de la publicité, du marketing et de la revente de données.
node cookies/set-cookie.js
'use strict';
const {createServer} = require('http');
const server = createServer().listen(4000);
server.on('request', (request, response) => {
response.setHeader('Set-Cookie', 'compteur=1'); // (1)
response.end();
});-
L’en-tête de réponse
Set-Cookiecrée/modifie la valeur d’un cookie chez le client – ici, le cookiecompteurest créé avec la valeur1.
Nous pouvons observer la création du cookie en nous rendant sur localhost:4000 avec un navigateur, puis en ouvrant les outils de développement.

Les cookies sont transmis du client au serveur à chaque requête.
node cookies/read.js
'use strict';
const {createServer} = require('http');
const server = createServer().listen(4000);
server.on('request', (request, response) => {
const cookie = request.headers.cookie; // (1)
response.end(`Contenu : ${cookie}`); // (2)
});-
Les cookies se lisent en inspectant l’en-tête de requête
Cookie. -
Affiche
Contenu : compteur=1. intexterm:[HTTP, en-tête, Cookie] intexterm:[application web, cookie]
Nous avons récupéré la valeur de l’en-tête contenant le cookie. Nous devons faire un effort supplémentaire pour transformer cette valeur textuelle en une structure ECMAScript qui fait sens pour notre application.
Nous allons nous aider pour cela du module npm cookie
(npmjs.com/cookie).
Il sait interpréter le contenu d’un en-tête HTTP et il sait également faire
l’inverse, transformer une structure ECMAScript vers du texte utilisable
dans l’en-tête de réponse Set-Cookie.
node cookies/parse.js
'use strict';
const {createServer} = require('http');
const {parse} = require('cookie');
const server = createServer().listen(4000);
server.on('request', (request, response) => {
const cookies = parse(request.headers.cookie); // (1)
response.end(JSON.stringify(cookies)); // (2)
});-
Nous passons l’intégralité de l’en-tête de requête
Cookieà la fonctioncookie.parse. -
Affiche
{"compteur":"1"}.
La méthode response.setHeader() accepte un tableau pour créer plusieurs
cookies en même temps :
node cookies/set-multiple.js
'use strict';
const {createServer} = require('http');
const {parse, serialize} = require('cookie');
const server = createServer().listen(4000);
server.on('request', (request, response) => {
const {compteur} = parse(request.headers.cookie);
const compteur2 = Number(compteur) + 1;
response.setHeader('Set-Cookie', [ // (1)
'language=fr; Max-Age: 9000000', // (2)
'is_admin=1; Path=/admin; HttpOnly', // (3)
serialize('compteur', compteur2, {httpOnly: true}), // (4)
//`compteur=${compteur2}; HttpOnly` // (5)
]);
response.end();
});-
Nous créons plusieurs cookies en passant un tableau de valeurs à la méthode
response.setHeader(). -
Crée un cookie dont la durée est limitée à 9 millions de secondes (~104 jours).
-
Crée un cookie visible pour le chemin d’accès
/path(et les sous-chemins) – la deuxième directive empêche les scripts clients d’en lire ou modifier la valeur. -
L’utilisation de
cookie.serialize()est une autre manière de créer des cookies en construisant un objet ECMAScript au lieu d’une chaîne de caractères. -
La ligne précédente équivaut à l’écriture de cette ligne.
Cet exemple est aussi l’occasion de compléter les cookies avec des directives, qui modifient leur durée de vie et leur visibilité.
Cela s’observe en lançant à nouveau le script cookies/parse.js :
node cookies/parse.js
L’accès à localhost:4000 affiche quelque chose comme {"compteur":"1","language":"fr"}
tandis que localhost:4000/admin affiche un cookie supplémentaire –
{"is_admin":"1","compteur":"1","language":"fr"}.
| Directive | Explication |
|---|---|
|
Durée de vie du cookie en secondes. |
|
Spécifie le domaine ou les sous-domaines applicables au cookie. |
|
Contraint le cookie à ce répertoire et tous ses sous-répertoires. |
|
Le cookie est envoyé seulement si le document est demandé via HTTPS. |
|
Le cookie ne peut pas être lu ou modifié côté client, via la variable |
Nous savons maintenant garder le lien avec nos utilisateurs. Nous utiliserons d’ailleurs les cookies pour maintenir une session avec un framework web.
8.8. Structurer l’affichage avec les gabarits de présentation
Les gabarits de présentation (ou templates) répondent à deux problèmes : séparer le code applicatif (le fond) de la présentation (la forme) et aussi structurer la complexité visuelle avec des composants réutilisables.
Nous allons nous pencher sur le module nunjucks (npmjs.com/nunjucks). Je l’apprécie pour son élégance et pour son caractère extensible. Il existe d'autres modules de présentation bien sûr et je vous invite à choisir celui qui vous parle le plus, quitte à en changer par la suite.
J’attends plusieurs choses d’un système de gabarits : itérer facilement
sur des collections (tableaux, objets), appliquer des filtres, inclure des
portions de présentation et imbriquer ma page dans un modèle de présentation
– une sorte de décoration qui contient des choses que je veux garder hors du gabarit
(comme le menu principal ou les balises <meta>).
Dans la suite de cette section, nous allons créer une présentation à partir
d’une liste de modules npm contenue dans un fichier JSON.
L’image suivante illustre très bien ce que nous cherchons à atteindre.

'use strict';
const {createServer} = require('http');
const {dependencies} = require('./package.json');
const njk = require('nunjucks').configure(__dirname); // (1)
const onRequest = (request, response) => {
const html = njk.render('list.njk', { // (2)
title: 'Liste des dépendances',
dependencies
});
response.end(html); // (3)
};
createServer(onRequest).listen(4000);-
Nous configurons le module nunjucks pour qu’il cherche les gabarits dans le même répertoire que le script de l’application.
-
La méthode
render()prend le contenu du fichierlist.njkainsi que les variables passées en argument pour compiler du HTML. -
Ce HTML est envoyé en réponse pour être interprété par un navigateur web.
Dans cet exemple, nous répondons la même chose, peu importe le chemin demandé au serveur. Nous pourrions tout à fait ajouter un routeur afin de répondre avec un gabarit différent pour chacune des routes. Nous verrons aussi dans la section “Organiser une application” qu’un des buts des frameworks est d’apporter ce genre de cohérence.
Côté serveur, nous prenons une structure qui ne change pas (le gabarit) et nous la combinons avec une structure qui change (les données) pour générer un rendu HTML adapté au client à l’origine de la requête.
{% extends "layout.njk" %} <!--(1)-->
{% block content %} <!--(2)-->
<p>
Il y a {{ dependencies | length }} modules <!--(3)-->
dans le fichier <code>package.json</code>.
</p>
<ul>
{% for pkg,version in dependencies %} <!--(4)-->
<li><code>{{ pkg }}@{{ version }}</code></li> <!--(5)-->
{% endfor %}
</ul>
{% endblock %}-
Nous indiquons à nunjuck d’envelopper ce gabarit avec la structure décrite dans
layout.njk. -
Début de la déclaration d’un bloc nommé
content. -
L’objet
dependencies(qui est passé en paramètre au gabarit) est affiché après avoir été filtré avec la fonction native nunjuckslength. -
La boucle
forrépète le bloc de gabarit pour chaque élément de la collection – à la manière des méthodesmap()etforEachdes tableaux ECMAScript. -
Les valeurs de
pkget deversionchangent à chaque itération.
Le gabarit se concentre sur la transformation de données. Il faut au préalable avoir réuni et structuré les données nécessaires à l’affichage. Nous avons la possibilité de fragmenter notre code de sorte que chaque gabarit contienne uniquement ce qui dépend de sa responsabilité.
Nous retrouvons ces principes de fonctionnement dans d’autres langages, à quelques variations près.
{% … %}
|
Expression nunjucks qui marque le début ou la fin d’un bloc. Ce dernier contient une expression dont le contenu est affiché, inclus ou répété selon certaines conditions. |
{{ variable }}
|
Affichage de la valeur d’une variable sous forme d’une chaîne de caractères. |
{{ variable | filtre }}
|
Affichage de la valeur d’une variable après application d’un filtre de transformation. Ce dernier n’est autre qu’une fonction ECMAScript intégrée au mécanisme de nunjucks. Nous pouvons accumuler les filtres pour transformer la valeur jusqu’à obtenir le résultat attendu. |
Intéressons-nous maintenant au gabarit parent, layout.njk :
<!DOCTYPE html>
<html lang="fr">
<meta charset="utf-8">
<head>
<title>{{ title }}</title> <!--(1)-->
</head>
<body>
<h1>{{ title }}</h1>
{% block content %}{% endblock %} <!--(2)-->
</body>
</html>-
La variable
titleest un argument passé au gabarit danstemplating/server.js. -
Le bloc
contentdéfini dans le fichierlist.njkest injecté à cet endroit du gabarit.
Ce gabarit sert de “décoration”, en englobant puis injectant son contenu de manière précise et contrôlée. Nous sommes en mesure de hiérarchiser l’organisation de la présentation et de choisir comment imbriquer les gabarits entre eux.
|
💬
|
Documentation Gabarit et API
La documentation complète des fonctions de gabarit se trouve sur mozilla.github.io/nunjucks/templating.html. La section API vous aidera à ajuster son intégration à votre application Node. |
| Module | Adresse | Pourquoi l’utiliser ? |
|---|---|---|
ejs |
Pour écrire ses gabarits avec ECMAScript. |
|
handlebars |
Performant, éprouvé et large catalogue de filtres prêts à l’emploi. |
|
nunjucks |
Mécanisme élégant de blocs, de filtres et d’héritage de gabarit. |
|
pug |
Écriture très concise des balises avec un système d’indentation. |
|
react |
Pour réutiliser les mêmes composants que le front-end. |
Nous détaillons des exemples de rendu de gabarit en annexe A.
8.9. Pendant le développement : relancer le serveur automatiquement
Vous avez modifié un des exemples de ce chapitre pendant qu’il était en cours d’exécution et vous avez remarqué que résultat ne changeait pas ?
C’est normal : la version du code utilisée par Node est celle qui a été évaluée au lancement du script. Les changements sont pris en compte manuellement, à la prochaine exécution, c’est-à-dire après avoir stoppé et lancé à nouveau le script.
Le module npm exécutable nodemon (npmjs.com/nodemon)
relance automatiquement une commande dès qu’il détecte un changement
dans le répertoire courant.
nodemon cookies/parse.js au lieu de "node cookies/parse.js"
La commande précédente relance cookies/parse.js si ce fichier change,
si un fichier dans le répertoire cookies/ évolue, mais aussi si un fichier
dans les répertoires voisins au répertoire cookies/ est modifié.
L’option --watch restreint ou élargit le champ d’observation.
La commande suivante relance le serveur seulement si un fichier JavaScript
est modifié dans le répertoire cookies/ :
nodemon --watch cookies cookies/parse.js
L’option --ext filtre les fichiers observés en fonction de leur type.
La commande suivante relance le serveur si un fichier JavaScript, CSS ou HTML
est modifié dans le répertoire courant :
nodemon --ext js,css,html cookies/parse.js
|
💬
|
Question Installation globale ou installation locale ?
Vous n’êtes pas sûr·e de la meilleure manière d’installer et d’utiliser
le module nodemon ?
Je vous invite à relire la section
“Exécutable système”
du chapitre 5 consacré à |
9. Organiser une application avec le framework Express
La section précédente a détaillé un ensemble de fonctionnalités individuelles qui permettent à la fois de mieux comprendre comment fonctionne HTTP, mais aussi comment constituer des briques d’une application web avec Node.
Les frameworks applicatifs web sont des outils qui proposent de créer une cohérence dans l’organisation de ces fonctionnalités, de sorte que nos efforts se concentrent plus sur l’écriture du code et moins sur la création du cadre.
Dans cette section, je vous propose d’appliquer ces connaissances au framework Express (npmjs.com/express). C’est un outil flexible et bien documenté, un choix de prédilection pour commencer.
Vous pouvez vous en tenir à ce framework ou bien évoluer ou compléter son utilisation avec fastify (plus récent et plus rapide), restify (orienté API REST), koa (asynchrone et plus rapide) ou encore hapi (plus structuré et plus complexe).
J’ai une préférence pour les outils qui ne font pas trop de choix à notre place,
bien documentés et, si possible, qui travaillent autour du
module http – cela conserve une certaine
clarté autour des concepts que nous manipulons.
9.1. Configuration du framework
La configuration initiale d'Express définit un serveur HTTP – à la manière
de ce que nous faisions avec http.createServer() – et retourne
un routeur pour attacher des comportements à des chemins d’accès.
node framework/setup.js
'use strict';
const app = require('express')(); // (1)
app.get('/', (request, response) => { // (2)
response.send('<a href="/login">connexion</a>');// (3)
});
app.get('/login', (request, response) => {
response.send('<p>En travaux</p>');
});
app.listen(4000); // (4)-
Création de l’application Express.
-
Déclaration d’une route pour la page d’accueil.
-
La méthode
response.send()est un raccourci qui combine et configureresponse.write(),response.statusCodeet deresponse.end(). -
Branchement du serveur HTTP sur l’interface réseau du système d’exploitation.
C’est vraiment très proche de ce que nous avons déjà appris à faire dans les sections “Démarrer un serveur HTTP” et “Répondre à un chemin”.
|
💬
|
Documentation Quelles méthodes et pour quoi faire ?
La documentation d’Express est le meilleur endroit pour savoir quoi faire avec les différents objets du module. Sa lecture vous aidera à mieux suivre cette section car vous comprendrez d’où sortent les méthodes utilisées.
|
9.2. Greffer des extensions (middlewares)
Un des premiers éléments différenciant est le branchement d’extensions. Une fois configurées, ces extensions s’appliquent à chaque requête entrante. Elles ajoutent des capacités de compréhension de la requête (parser des données de formulaire par exemple), de modifier la réponse ou de connecter des gabarits de présentation.
Chaque couche de transformation est appelée un middleware – une fonction intermédiaire entre la requête et la réponse.
node framework/middleware.js
'use strict';
const app = require('express')();
const {random} = require('pokemon');
app.use((request, response, next) => { // (1)
response.locals.pokemon = random(); // (2)
next(); // (3)
});
app.get('/', (request, response) => {
const {pokemon} = response.locals; // (4)
response.send(`Pokémon aléatoire : ${pokemon}`);// (5)
});
app.listen(4000);-
Un middleware se branche avec la méthode
app.use(). -
L’objet
response.localspasse des données jusqu’à la route – qui sont effacées une fois la réponse envoyée. -
La fonction
next()passe la main au prochain middleware. -
Nous récupérons l’objet
response.locals.pokemoncréé par notre middleware. -
Affichage d’un message similaire à
Pokémon aléatoire : Patrat.
Un middleware n’est pas très différent d’une route : c’est une fonction
qui a accès à la requête et à la réponse HTTP.
Elle n’est pas forcément affectée à une méthode HTTP (app.get(), app.post())
ni à un chemin d’accès.
Dans l’exemple suivant, nous allons connecter plusieurs middlewares grâce
aux modules npm helmet (npmjs.com/helmet) et serve-static
(npmjs.com/serve-static).
Ce dernier est une version embarquée de serve par le module Express.
node framework/middleware-multi.js
'use strict';
const express = require('express');
const helmet = require('helmet');
const {join} = require('path');
const app = express();
const filepath = join(__dirname, '..', 'static', 'files');
app.use('/files', express.static(filepath)); // (1)
app.use(helmet()); // (2)
app.get('/', (request, response) => {
response.send('<img src="/files/screenshot.jpg">'); // (3)
});
app.listen(4000);-
Nous branchons le middleware utilisé dans la section répondre avec des fichiers statiques sur l’URL
{serveUrl}/files. -
Nous branchons les middlewares de sécurité à notre application.
-
La racine de l’application affiche une image contenue dans un autre répertoire.
Le mécanisme de middlewares est minimaliste, et pourtant, il nous permet de brancher des modules dont le seul pré-requis est de comprendre les objets de requête et de réponse HTTP. Les middlewares relient tous les concepts évoqués dans la section “Composer son application web”.
curl --head http://localhost:4000 HTTP/1.1 200 OK X-DNS-Prefetch-Control: off X-Frame-Options: SAMEORIGIN Strict-Transport-Security: max-age=15552000; includeSubDomains X-Download-Options: noopen X-Content-Type-Options: nosniff X-XSS-Protection: 1; mode=block Content-Type: text/html; charset=utf-8 Content-Length: 33 ETag: W/"21-tmPtjMCysQ8MzbRDY67vN+isCos" Date: Sun, 15 Jul 2018 17:12:48 GMT Connection: keep-alive
Le module helmet agit seulement sur les en-têtes de réponse. Nous verrons dans la section “Protéger nos applications” quels en-têtes sont essentiels à la sécurité et pourquoi.
Enfin, notons une méthode alternative pour appliquer un middleware : au niveau
d’une route, au lieu de toutes les routes – avec app.use().
Pour cela, nous allons transformer l’exemple framework/middleware.js et
l’appliquer à une seule route :
node framework/middleware-function.js
'use strict';
const app = require('express')();
const {random} = require('pokemon');
const pokéMiddleware = (request, response, next) => {
response.locals.pokemon = random();
next();
};
const affichePoké = (request, response) => { // (1)
const {pokemon} = response.locals;
response.send(`Pokémon aléatoire : ${pokemon}`);
};
app.get('/', pokéMiddleware, affichePoké); // (2)
app.get('/rondoudou', affichePoké); // (3)
app.listen(4000);-
Nous avons factorisé la route dans une fonction afin de la rendre réutilisable.
-
La route
/reçoit d’abord le middleware, puis la fonction d’affichage. -
La route
/rondoudoureçoit uniquement la fonction d’affichage.
Nous verrons que, même si la fonction d’affichage est identique, les routes
localhost:4000/ et localhost:4000/rondoudou produisent des résultats différents.
Cette dernière n’ayant pas reçu le middleware pokéMiddleware, sa variable
response.locals.pokemon n’a pas été définie et elle vaut donc undefined.
9.3. Brancher les gabarits de présentation
La configuration des gabarits de présentation n’est pas très différente de ce que nous avons vu dans la section qui leur est consacrée.
node framework/templating.js
'use strict';
const app = require('express')();
const njk = require('nunjucks').configure(__dirname); // (1)
njk.express(app); // (2)
app.get('/', (request, response) => {
response.render('index.njk', { message: 'Coucou !' });// (3)
});
app.listen(4000);-
Configuration de nunjucks, comme dans la section “structurer l’affichage avec les gabarits de présentation”.
-
Utilisation de la méthode
express()pour laisser à nunjucks le travail de configuration d’Express. -
Nous appelons la méthode
response.render()au lieu deresponse.send()– elle charge le gabarit donné et lui passe un objet dont chaque clé devient une variable.
Nous avons de la chance car nunjucks prend en charge toute la configuration
d'Express pour nous.
La seule différence avec les précédents exemples est l’utilisation de la
méthode response.render().
Le premier effet que cela me fait est une sensation de légèreté – nous avons
le strict minimum à gérer pour que cela fonctionne.
En comparaison, voici comment Express se configure à la main :
node framework/templating-manual.js
'use strict';
const app = require('express')();
const njk = require('nunjucks');
app.set('views', __dirname); // (1)
app.engine('njk', (file, options, next) => { // (2)
const html = njk.render(file, options); // (3)
next(null, html); // (4)
});
app.get('/', (request, response) => {
response.render('index.njk', { message: 'Coucou !' });
});
app.listen(4000);-
On indique à Express de contextualiser le répertoire racine où se trouvent les gabarits.
-
Déclaration de la fonction de rendu pour les fichiers
.njk– elle est lancée à chaque fois queresponse.render()est appelée avec un fichier.njk. -
Rendu du fichier passé en paramètre.
-
Le HTML généré est passé à la fonction de rappel
next()– le premier argument est utilisé pour transmettre une erreur, le second le résultat en cas de succès.
Cette méthode demande davantage de travail. Elle implique aussi d’être suffisamment familier·ère avec Express pour en venir à créer cette fonction de rendu.
Au final, nous pourrions utiliser différents moteurs de gabarits si le besoin se faisait ressentir, pour les exploiter à leur(s) avantage(s). Leur intégration demande un effort minimum et retire tous les aspects de présentation de la configuration du routeur.
|
💡
|
Pratique Un module pour les présenter tous
Le module Il vous sera utile si vous peinez à configurer Express avec votre moteur de gabarits favori. |
9.4. Intégrer les ressources front-end (CSS, images, JavaScript)
La gestion des ressources front-end ne demande pas à changer nos habitudes. Les fichiers CSS, JavaScript et les images sont des fichiers statiques à mettre à disposition via un middleware.
node framework/assets.js
'use strict';
const express = require('express');
const app = express();
const {join} = require('path');
const files_dir = join(__dirname, '..', 'static', 'files');
app.use('/static', express.static(files_dir)); // (1)
app.get('/', (request, response) => {
response.write('<img src="/static/screenshot.jpg">'); // (2)
response.end();
});
app.listen(4000);-
La méthode
express.static()configure le modulenpmsend. -
Affichage d’une image dont la source
screenshot.jpgest à la racine du répertoire virtuel/static.
J’ai tendance à exposer les fichiers statiques depuis un répertoire virtuel dédié
– ici, /static.
Cela rend plus clairement identifiables et évite toute ambiguïté avec les
autres routes de l’application.
Cela a aussi l’avantage de dissocier les fichiers sources (Sass, Less, etc.)
des fichiers compilés.
Dans le chapitre 5, j’explique comment
automatiser l’outillage projet.
Ces connaissances s’appliquent dans notre cas de figure, sans distinction.
L’extrait suivant de fichier package.json illustre l’organisation
des scripts pour démarrer le site en temps normal, pour générer les fichiers
compilés et pour le faire en continu dans un contexte de développement.
{
"...": "...",
"scripts": {
"build": "npm-run-all 'build:*'",
"build:css": "node-sass ./assets --output ./assets",
"start": "node assets.js",
"...": "...",
"dev": "npm-run-all 'watch:*'",
"watch:server": "nodemon assets.js",
"watch:css": "npm run build:css -- --watch --source-map"
}
}La première partie est dédiée aux scripts dits “de production” :
npm run build génère les fichiers utiles quand le serveur tourne,
après avoir lancé npm start.
La seconde partie lance le serveur de développement et la construction
des fichiers Sass en continu avec l’option --watch.
L’option --source-map s’utilisent dans un contexte de développement pour
associer les lignes du fichier compilé aux fichiers sources.
Les doubles tirets (--) nous permettent de réutiliser le script
build:css en lui passant deux options supplémentaires.
Le middleware statique s’utilise aussi avec des fichiers.
node framework/assets-file.js
'use strict';
const express = require('express');
const app = express();
const {join} = require('path');
const files_dir = join(__dirname, '..', 'static', 'files');
const image_path = join(files_dir, 'screenshot.jpg');
app.use('/wikipedia.jpg', express.static(image_path)); // (1)
app.get('/', (request, response) => {
response.write('<img src="/wikipedia.jpg">'); // (2)
response.end();
});
app.listen(4000);-
Nous définissions le fichier statique
/wikipedia.jpgalors qu’il était initialement nomméscreenshot.jpg. -
Ce chemin d’accès affiche bien l’image attendue.
Cette technique est utilisable pour exposer un seul fichier au lieu d’un répertoire entier.
Enfin, le module npm express-minify (npmjs.com/express-minify)
est à considérer pour profiter d’une mise en place rapide ou
pour prototyper quelque chose en attendant de mettre en place un outillage
plus robuste.
node framework/minify.js
'use strict';
const express = require('express');
const app = express();
const minify = require('express-minify');
const {join} = require('path');
express.static.mime.define({ 'text/x-scss': ['scss'] });// (1)
app.use(minify()); // (2)
app.use('/static', express.static(join(__dirname, 'assets')));
app.get('/', (request, response) => {
response.write(
'<link rel="stylesheet" href="/static/main.scss">' // (3)
);
response.end('<p>Coucou !</p>');
});
app.listen(4000);-
Le module express-minify transforme les fichiers Sass si leur en-tête de réponse
Content-Typevauttext/x-scss– cette ligne affecte cet en-tête aux fichiers dont l’extension est.scss. -
Ajout du module comme middleware.
-
Le fichier
main.scsssera converti en CSS.
Si ce module permet de démarrer plus vite, sans avoir à se familiariser
avec les scripts npm ni même avec la commande node-sass,
je lui vois deux inconvénients majeurs : les erreurs sont difficiles à déceler
et elles risquent de se produire au cas où notre machine de développement est
significativement différente du serveur de production (compilateur,
installation manquée).
Cela représente aussi un gâchis de ressources dans la mesure où ces fichiers
ne changent plus une fois mis en ligne ; cela ne justifie pas d’ajouter
du temps de compilation à la volée.
En clair, c’est pratique pour dépanner et pour démarrer.
9.5. Brancher une base de données
L’utilisation d’une base de données sert à mémoriser des informations entre deux redémarrages de notre application – sinon, ce qui est en mémoire applicative disparaît. Je vous recommande de lire la section “Quel(s) moteur(s) de base(s) de données choisir ?” pour éclairer votre choix.
node framework/database.js
'use strict';
const app = require('express')();
const sqlite = require('sqlite');
const {join} = require('path');
sqlite.open(join(__dirname, 'db.sqlite')).then(db => { // (1)
app.get('/', (req, res) => res.redirect('book/1'));
app.get('/book/:id', (request, response) => {
const {id} = request.params;
db.get('SELECT * from books WHERE id = ?', id) // (2)
.then(record => { // (3)
record
? response.send(record) // (4)
: response.status(404).send('Livre inconnu');
});
});
app.listen(4000);
});-
La connexion à la base de données est asynchrone – l’objet
dbqui permet d’exécuter des requêtes est renvoyé par la promesse. -
Exécution d’une requête avec un paramètre issu du routage – le champ
:id. -
Le résultat est fourni lors de la résolution de la promesse – il vaut
undefinedsi aucun enregistrement n’a été trouvé. -
Affichage de l’enregistrement côté client (sans mise en forme aucune).
L’intégration d’une base de données se fait en deux temps :
-
D’abord, on ouvre une connexion asynchrone. Les connexions HTTP sont acceptées seulement si la connexion à la base réussit.
-
La réponse est renvoyée après avoir fait un aller-retour vers la base afin d’en extraire un ou plusieurs résultat(s).
|
⚠️
|
Sécurité Systématiser les emplacements de paramètre
L’utilisation des emplacements de paramètre dans les requêtes SQL avec
le caractère La valeur est filtrée pour éviter de déjouer le moteur de base de données en le faisant planter ou en exposant davantage d’informations que prévues. |
Nous verrons dans la section “Vers un code réutilisable et testable” qu’un des enjeux est de rendre le fichier de démarrage le plus fin possible.
9.6. Sessions utilisateurs
Nous avons appris à mémoriser des données et à les partager avec un serveur grâce au mécanisme des cookies. Les sessions utilisateur centralisent cette mémoire du côté du serveur. Elles se basent sur un cookie de session pour garder un lien.
Les sessions sont destinées à stocker des données temporaires, liées à une personne. Un utilisateur peut avoir plusieurs sessions – une par appareil par exemple. Chaque session est propre à son environnement immédiat. Elles sont pratiques pour mémoriser des informations liées à un état (connecté·e, déconnecté·e, date de dernière activité).
Tout stockage qui serait permanent relève des préférences utilisateur.
L’extension express-session (npmjs.com/express-session)
se charge de ce travail pour nous.
Il ajoute un élément request.session qu’il mémorise et récupère à partir
d’un identifiant de session difficile à deviner.
node framework/session.js
'use strict';
const app = require('express')();
const session = require('express-session');
const {random} = require('pokemon');
app.use(session({ secret: 'fromage' })); // (1)
app.get('/', (req, res) => {
req.session.pokemon = random(); // (2)
res.redirect('my-pokemon');
});
app.get('/my-pokemon', (request, response) => {
const {pokemon} = request.session;
response.send(`Mon Pokémon en session : ${pokemon}`);// (3)
});
app.listen(4000);-
Configuration du middleware avec un secret qui rend moins prévisible le nom du cookie.
-
Création d’une donnée de session nommée
pokemon, de valeur aléatoire. -
Affiche un message similaire à
Mon Pokémon en session : Pikachu.
La même valeur s’affiche si vous ouvrez un nouvel onglet dans le même navigateur et en vous rendant sur localhost:4000/my-pokemon. Le serveur fait le lien entre votre identifiant de session (stocké en cookie) et les valeurs associées (stockées en mémoire, pour l’instant) grâce à un identifiant unique stocké dans le cookie de session.
Le middleware de session retrouve les informations associées à cet identifiant depuis l’espace de stockage des données de sessions.
curl -i -L http://localhost:4000 HTTP/1.1 302 Found Location: my-pokemon Content-Type: text/plain; charset=utf-8 Content-Length: 32 set-cookie: connect.sid=s%3AWfP...SRr5Q; Path=/; HttpOnly Date: Tue, 17 Jul 2018 09:46:15 GMT
Le seul inconvénient à notre exemple est que, si nous stoppons puis relançons
le serveur, la page localhost:4000/my-pokemon affiche
undefined comme nom de Pokémon.
C’est normal : le stockage par défaut étant en mémoire, les données de session
sont détruites dès que le processus Node s’interrompt.
Fort heureusement pour nous, ces données se stockent avec la base de données de notre choix. Nous allons utiliser le moteur de base de données SQLite à l’aide du module connect-sqlite3 (npmjs.com/connect-sqlite3) pour illustrer la persistance des données de session.
node framework/session-database.js
'use strict';
const app = require('express')();
const session = require('express-session');
const SQLiteStore = require('connect-sqlite3')(session);// (1)
const {random} = require('pokemon');
app.use(session({
secret: 'fromage',
store: new SQLiteStore('./sessions') // (2)
}));
app.get('/', (req, res) => {
req.session.pokemon = random(); // (3)
res.redirect('my-pokemon');
});
app.get('/my-pokemon', (request, response) => {
const {pokemon} = request.session;
response.send(`Mon Pokémon en session : ${pokemon}`);
});
app.listen(4000);-
Branchement du module de stockage au gestionnaire de sessions d'Express.
-
Configuration du connecteur de stockage et de l’emplacement du fichier qui contient les données des sessions.
-
L’écriture et la lecture des données de session est inchangée.
Cette fois, si nous stoppons le serveur puis le relançons, le gestionnaire de sessions affiche le nom de Pokémon associé à notre identifiant. La persistance a fonctionné !
9.7. Tracer les actions (logs)
Consigner les actions (logging en anglais) est une pratique courante en informatique pour créer une mémoire de l’activité d’une application. Ces consignes aident à garder des traces de choses invisibles en surface, d’événements sensibles ou critiques (envoi de mot de passe, création de compte) afin de détecter des anomalies de fréquence.
C’est un endroit idéal pour répertorier les erreurs avec des indications qui aideraient à reproduire le problème. D’ailleurs, l’usage est de tenir un journal d’erreurs séparé du journal des événements afin de retrouver plus facilement ces premières. J’ai tendance à préférer l’installation d’une sonde (section “S’informer des erreurs applicatives” du chapitre 6).
C’est à nous de choisir la granularité des informations enregistrées. Nous sommes responsables de l’anonymat de ces informations et de ne rendre personnel que l’identifiant (numérique ou généré) pour rattacher des informations à un utilisateur si c’est nécessaire – dans le cas de transaction bancaire ou de renvoi de mot de passe par exemple.
|
⚠️
|
Attention Rotation de logs
Consigner des informations est bien jusqu’au moment où l’historique finit par saturer le disque dur de la machine qui héberge l’application. Sous Linux, le logiciel logrotate (doc.ubuntu-fr.org/logrotate) est souvent installé par défaut. Il indique au système quand tronquer le fichier d’historique – tous les X mégaoctets, tous les X jours. |
Les modules npm pour consigner nos actions fonctionnent comme des
console.log() finement configurables : winston (npmjs.com/winston),
morgan (npmjs.com/morgan) et bunyan (npmjs.com/bunyan)
sont à essayer, pour voir celui qui vous convient le mieux.
Les journaux de sortie se connectent à des logiciels comme rsyslog (rsyslog.com) ou à des services en ligne comme Papertrail (papertrailapp.com), Logstash (elastic.co/products/logstash) et AWS CloudWatch (aws.amazon.com/cloudwatch). Elles vous aident – ou vous demandent de travailler davantage – pour visualiser, orchestrer et déclencher des actions quand des valeurs spécifiques sont rencontrées dans les journaux.
10. Vers un code réutilisable et testable
L’intention de cette section est de consolider les différents concepts évoqués au cours de ce chapitre. Nous avons composé pas à pas une application web jusqu’à l’organiser avec le framework Express. Maintenant, nous allons réorganiser les composants pour améliorer la maintenance et la robustesse aux changements de nos applications web.
Notre but ? Diminuer la taille du script de lancement, rendre les composants indépendants et préparer au mieux les données passées à nos gabarits pour faciliter l’écriture de tests et favoriser l’automatisation du déploiement.
10.1. Modulariser le code des routes
Le défi de lisibilité et de maintenance augmente au fur et à mesure que le volume de code augmente. C’est particulièrement vrai quand le nombre de lignes dépasse un seuil psychologique dans un même fichier – je commence à saturer au-delà de 100 lignes, par exemple. Ce phénomène se renforce quand plusieurs concepts s’entrecroisent visuellement.
La modularisation des routes et de notre application web va nous rendre la vie plus confortable. Nous ouvrons la porte à l’écriture de tests unitaires, à un déplacement plus aisé du code et à une quasi-disparition des variables globales. Nous en profitons pour rendre nos intentions explicites, ce à quoi nous obligent les réflexions de nommage de fichiers et de fonctions.
node modularity/01/server.js
'use strict';
const app = require('express')();
const dbPromise = require('./src/database.js'); // (1)
const routes = require('./src/routes.js'); // (2)
dbPromise.then(() => {
app.get('/books/:id', routes.books); // (3)
app.listen(4000);
});-
Nous déplaçons la configuration de et la connexion à la base de données dans son propre module.
-
Nous déplaçons aussi le code des routes.
-
Au premier coup d’œil, la route est une association de chemin et d’une fonction.
Nous créons des modules qui retournent des fonctions ou des objets. Nous connectons ensuite ces fonctions aux chemins d’accès du routeur.
Profitons du mécanisme de promesses pour que tout autre module puisse réagir à l’aboutissement de la connexion :
'use strict';
const sqlite = require('sqlite');
const {join} = require('path');
const db_dir = join(
__dirname, '..', '..', '..', 'framework' // (1)
);
module.exports = sqlite.open(join(db_dir, 'db.sqlite'));// (2)-
Nous réutilisons la base de données d’un exemple précédent.
-
La fonction
sqlite.open()retourne une promesse résolue lorsque la connexion à la base est établie.
Notons que nous exploitons le mécanisme de cache
des modules Node dans cette dernière ligne.
Chaque appel au fichier database.js retourne la même promesse.
Nous créons ainsi une seule connexion à la base de données même si nous chargeons
plusieurs fois ce module.
Je trouve agréable de regrouper ce genre de lignes de code dans un même fichier.
Les dépendances aux modules Node et npm deviennent vraiment claires.
Je suis moins dérangé par l’organisation visuelle du code – elle aurait ralenti
ma lecture du fichier server.js autrement.
'use strict';
module.exports.books = require('./routes/books.js'); Le fichier de routes a vocation à réexporter les fonctions de routage. Je trouve que cette organisation sous forme de catalogue fait énormément gagner en lisibilité lors de l’intégration avec le routeur.
Le dernier morceau est la route elle-même :
'use strict';
const dbPromise = require('../database.js'); // (1)
module.exports = (request, response) => {
const {id} = request.params;
dbPromise.then(db => { // (2)
db.get('SELECT * from books WHERE id = ?', id)
.then(record => {
if (!record) {
return response.status(404).send('Livre inconnu');
}
response.send(record);
});
});
};-
Récupération de la promesse de connexion à la base de données – déjà pré-configurée.
-
De fait, l’exécution d’une requête dépend de la résolution de la connexion.
Le code de la route est quasi inchangé mais on voit à quel point elle prenait de la place dans le code d’origine. Ce déplacement révèle le positionnement du point d’attention et quels fichiers sont amenés à changer au quotidien. Peu importe l’organisation du vôtre, ce qui compte c’est que cette organisation vous convienne, qu’elle soit communicable aux personnes qui utilisent ce code et que nous puissions en suivre le fil logique.
Je vois toutefois apparaître une zone d’ombre : je ne suis pas satisfait de la connexion à la base de données. C’est la résolution de la promesse dans la route qui me fait dire ça ; elle ne semble pas à sa place.
Faisons une nouvelle itération pour ajuster ce code et tendre vers quelque chose d’un peu plus explicite.
node modularity/02/server.js
'use strict';
const app = require('express')();
const {dbPromise, routes} = require('./configure'); // (1)
dbPromise.then((db) => {
app.get('/books/:id', routes.books(db)); // (2)
app.listen(4000);
});-
Nous regroupons les éléments de configuration de l’application.
-
Nous passons les dépendances du module en argument – ici, l’objet de base de données.
La grande différence ici est l’invocation d’une fonction pour définir la route.
C’est le moyen le plus propre pour transmettre une variable en enlevant la
dépendance au module database.js dans le script books.js :
'use strict';
module.exports = (db) => { // (1)
return (request, response) => { // (2)
const {id} = request.params;
db.get('SELECT * from books WHERE id = ?', id)
.then(record => {
if (!record) {
return response.status(404).send('Livre inconnu');
}
response.send(record);
});
};
};-
Cette fois, nous exportons une fonction qui accepte un objet de base de données en argument.
-
Le code exécuté par le routeur est la fonction qui est retournée ici.
L’appel à la fonction require() a disparu.
La résolution de la promesse aussi.
Notre module est autonome tant qu’il reçoit un objet de base de données en
paramètres.
Cela le rend nettement plus lisible – le code est désormais uniquement lié
à la réception d’une requête HTTP et à l’établissement d’une réponse.
'use strict';
const dbPromise = require('./src/database.js');
const routes = require('./src/routes.js');
module.exports = {dbPromise, routes}; // (1)-
Nous utilisons la syntaxe raccourcie de création d’objets pour les exporter en une seule fois.
Nous retrouvons le même mécanisme que celui rencontré dans le fichier routes.js.
Au final, le motif qui émerge est celui de l'encapsulation de code dans des fonctions paramétrables. Les paramètres sont les seuls points d’entrée. Les arguments font office de contrat et les fichiers font office de regroupement logique – de fonctions et d’objets.
Nous avons allégé le fichier server.js et rendu lisibles les points importants
de l’application : la connexion à la base de données, le rendu d’une route
et la configuration de l’application.
Ce travail va nous permettre de tester petit à petit les différents éléments
de l’application web, par ordre de criticité.
10.2. Un code testable est un code indépendant du framework
L’écriture de tests unitaires est influencée par et influence l’organisation de notre code en unités réutilisables. Ils accroissent la qualité, la confiance et la prédictibilité d’une éventuelle mise en ligne.
Cette section se déroule dans la continuité de la précédente. Nous allons préparer et mettre en place pas à pas un environnement de test pour vérifier les intentions de notre code.
Les tests unitaires sont destinés à couvrir les différents cas de figure des entrées et des sorties de nos fonctions. Nous testons leurs réactions aux arguments pour vérifier que nous obtenons le résultat attendu. Je teste en priorité le code critique, partagé (en tant que bibliothèque) et qui est au plus proche de l’interface utilisateur.
De quoi a-t-on besoin pour tester routes/books.js ?
La fonction qui est exportée par le module dépend d’une connexion établie
à une base de données et de deux objets – la requête entrante et la réponse sortante.
Nous avons aussi besoin d’écrire des assertions et, dans un premier temps, nous
allons utiliser le module dédié de Node.
'use strict';
const assert = require('assert').strict;
const configRoute = require('../src/routes/books.js');
assert.deepEqual(typeof configRoute, 'function'); // (1)
/*
const db = require('../src/database.js'); // (2)
const route = configRoute(db);
assert.deepEqual(route(request, response));
*/-
C’est notre première assertion – l’élément retourné par
routes/books.jsest une fonction. -
En commentaire : comment allons-nous nous connecter à la base de données ?
node testing/tests/initial.js
Le script n’affiche rien de particulier. C’est normal, parce que le test s’est bien passé. Une assertion lance une erreur si elle constate un résultat différent de l’attente.
Nous avons toutefois testé une évidence, que le module retourne une fonction. Ce qui serait plus révélateur serait de tester l’invocation de cette fonction pour vérifier qu’elle produit un résultat prédictible.
Modifions notre fichier de test pour établir une connexion à la base de données. Nous avons une contrainte toutefois : nous devons utiliser une base dont l’emplacement est différent de notre environnement de développement. Le raisonnement est de pouvoir la recréer et la détruire sans craindre de générer des effets secondaires, y compris si nous exécutons les tests sur le serveur de production.
Pour ce faire, commençons par simplifier le fichier src/database.js en
supprimant tout chemin d’accès écrit en dur :
'use strict';
const sqlite = require('sqlite');
const connect = (db_path) => sqlite.open(db_path); // (1)
module.exports = connect; // (2)-
Le module n’a plus d’opinion sur l’emplacement de la base de données.
-
Le module exporte désormais une fonction à paramétrer lors de son exécution.
Cela ouvre la voie pour nous connecter à une base de données différente dans notre script de tests.
'use strict';
const assert = require('assert').strict;
const configRoute = require('../src/routes/books.js');
const database = require('../src/database.js');
// assert.deepEqual(typeof configRoute, 'function');// (1)
database(':memory:').then(db => { // (2)
const route = configRoute(db); // (3)
assert.deepEqual(typeof route, 'function'); // (4)
/*
assert.deepEqual(route(request, response)); // (5)
*/
});-
Nous pouvons nous passer de ce test puisque nous allons tester l’exécution de la fonction.
-
La valeur
:memory:est une valeur spéciale de chemin d’accès pour SQLite – la base est créée en mémoire et disparaît à la fin de l’exécution du script. -
Configuration de la route – comme nous le faisons dans le fichier
configure.js. -
La route configurée retourne bien une fonction, mais cela ne suffit pas à affirmer que son fonctionnement correspond à nos attentes.
-
En commentaire : comment tester le résultat de la route Express ?
Résultat : la connexion à la base de données réussit et nous sommes en mesure de la transmettre à la fonction de paramétrage de la route.
Le chemin d’accès était exprimé de la manière suivante : /books/:id.
Autrement dit, la requête à la base de données dépend d’un objet request.params
dont la clé id vaut 1.
C’est ce que nous allons passer à la fonction route.
Mais qu’en est-il de la réponse ? Doit-on réécrire un objet qui reproduit
l’objet response d'Express ?
Je déconseille cette option car elle nous oblige à écrire du code, faillible,
et donc à introduire des biais dans nos propres tests.
Les bibliothèques d’interception évitent ce cas de figure.
Elles se greffent à du code existant pour observer ses réactions, voire pour les
remplacer temporairement, le temps des tests.
J’ai l’habitude d’utiliser le module npm sinon.js (npmjs.com/sinon,
sinonjs.org/).
Il propose tout le nécessaire, est bien documenté et fonctionne aussi bien
côté Node que côté navigateurs web.
'use strict';
const assert = require('assert').strict;
const configRoute = require('../src/routes/books.js');
const database = require('../src/database.js');
const sinon = require('sinon');
const {response} = require('express'); // (1)
database(':memory:').then(db => {
const route = configRoute(db);
const sendFake = sinon.stub(response, 'send'); // (2)
return route({params: {id: 1}}, response).then(() => {
assert.ok(sendFake.called); // (3)
})
})
.catch(error => {
console.error(error.message);
process.exit(1);
});-
Nous récupérons l’objet de réponse d'Express – je l’ai découvert en fouillant dans les objets exportés par le module.
-
Nous neutralisons la fonction
response.send()avec un stub pour observer les données qui lui sont données en argument. -
La propriété
calledd’un stub ou d’un espion passe àtruesi elle a été appelée.
C’est une chance que le module Express expose directement un objet de réponse sans avoir à attendre qu’une vraie requête HTTP atteigne notre serveur web. Le stub neutralise son action – nous nous contentons d’observer comment la fonction est appelée. L’enjeu est de constater que la connexion à la base de données se passe bien, que la requête retourne bien la ligne attendue et que ses valeurs soient bien transmises en réponse.
Malheureusement pour nous : la base en mémoire n’a aucune donnée. Le test échoue donc. Notre nouvel objectif est de maintenir l’intention du test et de lui ajouter les données nécessaires à son exécution.
|
💬
|
Glossaire Espions, stubs et mocks
Les espions, stubs et mocks couvrent trois aspects complémentaires. Les espions enregistrent les appels à des attributs et à des fonctions – le nombre de fois, quels arguments, quels résultats. Les stubs interceptent les appels à des fonctions – vous pouvez même définir les valeurs de retours ou de rappel en fonction des paramètres d’appel. Les mocks interceptent les résultats – je n’en parle pas car notre exemple ne s’y prête pas. |
C’est la raison d’être des fichiers dits de fixtures. Ces données peuplent une base de données d’enregistrements suffisamment réalistes pour illustrer les différents cas de figure de notre application.
'use strict';
module.exports = async (db) => {
await db.run(`CREATE TABLE books
(id INTEGER PRIMARY KEY, title VARCHAR, isbn VARCHAR);`);
await db.run(`INSERT INTO books (title, isbn) VALUES
("Design Systems", "978-3945749586"),
("Sass pour les web designers", "977-2212141474"),
("Node.js", "978-2212139938");`);
return db;
}Ce cas est particulièrement adapté à la syntaxe
async/await.
Ces promesses sont séquentielles et la syntaxe linéarise leur lecture.
Le même exemple sans async/await et juste avec les promesses est moins
digeste à lire.
Il ne nous reste plus qu’à appeler cette fonction de génération de données depuis notre script de tests :
// ...
const loadFixtures = require('./fixtures.js'); // (1)
database(':memory:')
.then(db => loadFixtures(db)) // (2)
.then(db => {
const route = configRoute(db);
const sendFake = sinon.stub(response, 'send');
route({params: {id: 1}}, response).then(() => {
assert.ok(sendFake.calledWith(sinon.match({ // (3)
'title': 'Design Systems' // (4)
})));
})
});-
Chargement du module qui contient les requêtes SQL nécessaires à l’initialisation de la table et des données.
-
Les données sont chargées après la connexion à la base et avant l’exécution des tests.
-
Nous remplaçons l’appel à
sendFake.called()parsendFake.calledWith()pour affirmer plus explicitement le résultat attendu. -
Le module sinon propose un ensemble de fonctions de vérification (les matchers) – ici, nous vérifions que
response.send()est appelée avec un objet, qui contient au moins une clétitledont la valeur estDesign Systems.
Le test est concluant !
Et nous n’avons plus de doute que la fonction response.send()
est bien appelée avec la valeur issue de la base de données.
Le module sinon a été d’une grande aide pour intercepter l’exécution de cette
fonction et pour nous faciliter son introspection, après coup.
Pour être exhaustifs, il nous faudrait maintenant tester le deuxième cas de figure,
celui où le paramètre id de l’URL fait référence à un enregistrement qui
n’existe pas en base de données pour générer une erreur 404.
// ...
database(':memory:')
.then(db => loadFixtures(db))
.then(db => {
const route = configRoute(db);
const sendFake = sinon.stub(response, 'send');
const statusSpy = sinon.spy(response, 'status'); // (1)
route({params: {id: 1}}, response).then(() => {
assert.ok(sendFake.called);
});
route({params: {id: 4}}, response).then(() => { // (2)
assert.ok(statusSpy.calledWith(404)); // (3)
assert.ok(sendFake.calledWith('Livre inconnu'));// (4)
});
});-
Création d’un espion sur la méthode
response.status()du module Express. -
Création d’un deuxième cas de test, pour couvrir l’appel à un enregistrement inconnu en base de données.
-
La méthode
calledWith()détermine si une fonction est appelée avec cette exacte valeur. -
Cette méthode s’applique aussi aux stubs.
Dans ce cas, nous avons eu recours à un espion pour observer la méthode
response.status() d’Express.
Nous avons procédé ainsi car nous n’avions pas à neutraliser son fonctionnement
mais seulement à observer la valeur de son argument.
Le fait qu’il soit de 404 prouve que la branche de code à l’intérieur de la
condition if a bien été visitée.
Je constate un problème dans cette écriture cependant. L’espion et le stub sont créés une seule fois et partagés entre chaque test. Cette pratique entraînera des effets de bord si nous ne prêtons pas attention au déroulé des tests. Ils devraient être remis à zéro entre chaque test.
Les suites de tests sont des outils qui renforcent la cohérence
et la structure, notamment pour automatiser l’exécution d’actions avant et après
des tests.
J’utilise le module npm mocha (npmjs.com/mocha,
mochajs.org), par habitude, parce qu’il ne demande aucune
configuration et parce qu’il fait le travail à la fois côté Node et côté
navigateurs.
../node_modules/.bin/mocha testing/tests/with-mocha.js
'use strict';
const assert = require('assert').strict;
const configRoute = require('../src/routes/books.js');
const database = require('../src/database.js');
const sinon = require('sinon');
const {response} = require('express');
const loadFixtures = require('./fixtures.js');
const {describe, before, afterEach} = require('mocha'); // (1)
const {it:test} = require('mocha'); // (2)
// ...-
Import des fonctions qui décrivent respectivement la suite de tests, l’exécution de code avant le démarrage de la suite et l’exécution de code après chaque test.
-
Import de la fonction de test.
Notre script de test comporte désormais ce qu’on appelle une suite de tests, c’est-à-dire, un ensemble de tests qui expriment nos attentes vis-à-vis d’une fonctionnalité – ici, une route d’application web.
// ... (modules)
describe('routes/books.js', () => { // (1)
let db, route;
before(async () => { // (2)
db = await database(':memory:');
await loadFixtures(db);
route = configRoute(db);
});
afterEach(() => sinon.restore()); // (3)
// ...
});-
Déclaration de la suite de tests – sa valeur reflète généralement le sujet des tests.
-
Avant le démarrage des tests, nous créons la base de données et configurons la route.
-
Après chaque test, nous remettons à zéro l’état de sinon – nos tests n’ont plus la possibilité de se parasiter entre eux.
Ce découpage a le mérite de clarifier les différents temps de nos tests, à savoir la préparation de l’environnement d’exécution, le nettoyage puis l’exécution des tests.
// ... (modules)
describe('routes/books.js', () => { // (1)
// ... (configuration)
test('statut 200', () => { // (2)
const sendFake = sinon.stub(response, 'send');
return route({params: {id: 1}}, response).then(() => {
assert.ok(sendFake.calledWith(sinon.match({
'title': 'Design Systems'
})));
});
});
test('statut 404', () => { // (3)
const sendFake = sinon.stub(response, 'send');
const statusSpy = sinon.spy(response, 'status');
return route({params: {id: 4}}, response).then(() => {
assert.ok(statusSpy.calledWith(404));
assert.ok(sendFake.calledWith('Livre inconnu'));
});
});
});-
La suite compte deux tests.
-
Premier test : se termine quand la promesse retournée par la fonction
route()est résolue. -
Deuxième test : cette fois, l’espion et le stub ne sont pas affectés par le précédent test.
La suite de tests ne cherche pas à savoir comment nous testons notre code. Son objectif est de capturer les messages d’erreur des assertions qui échouent et de nous les communiquer en contexte.
|
⚠️
|
Réflexion Écriture optimiste
Nous avons l’habitude d’écrire des tests de manière optimiste. Ce biais naturel fait que nous ne testons pas les cas dont nous n’avons pas encore connaissance. Trouver les cas de figure qui font échouer notre code est un vrai travail de réflexion. |
L’approche Test Driven Development (TDD) est pilotée par les tests. Dans ce contexte, nous écrivons les tests avant même d’avoir écrit notre code. Cela nous force à réfléchir à l’intention et à concevoir le code de manière à ce qu’il soit testable. Qu’on adopte ou non cette méthode, nous gagnons en qualité en faisant échouer les tests, juste pour nous assurer que ce n’est pas un bogue (oui ça arrive) quand ils indiquent que tout est correct.
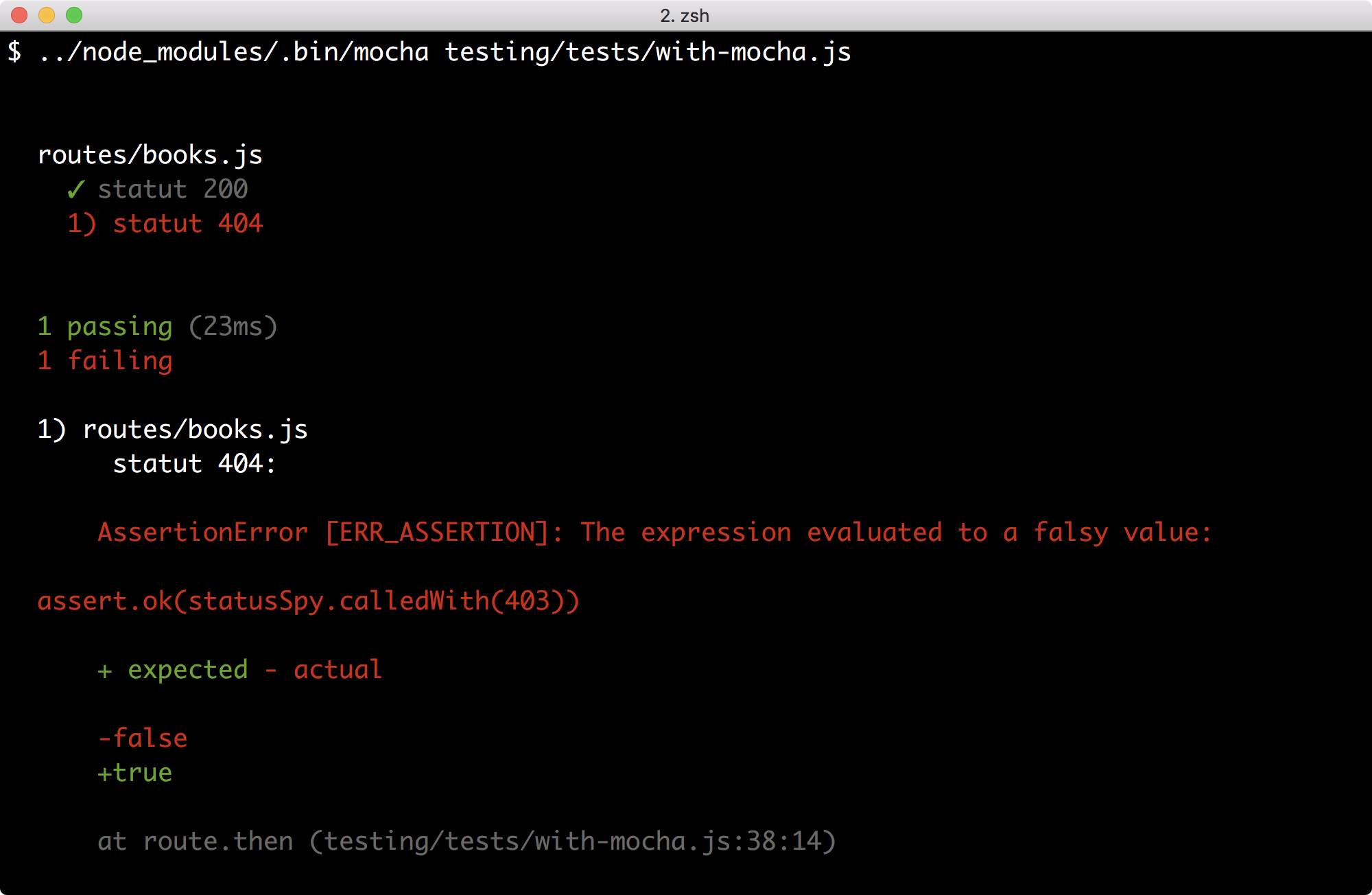
Maintenant que nos tests sont écrits, nous sommes en mesure de déployer notre application automatiquement, seulement si leur exécution est réussie.
10.3. Déployer automatiquement
Cette section continue à ajouter de l’automatisation dans notre manière de fonctionner. Elle n’est donc pas spécifique aux frameworks et est tout à fait valide si vous vous constituez votre propre application, brique par brique.
Le déploiement automatique sert principalement à révéler les points de friction. Si nous manquons de confiance dans le déploiement, c’est probablement qu’il y a des nœuds à démêler. L’automatisation du déploiement et la facilité de sa répétabilité nous aident à gommer ces frictions petit à petit. La pression de la mise en production se transforme en incitation au changement.
La fréquence des déploiements révèle les points de congestion. Tout ce qui est trop lent à notre goût est un appel à gommer cette lenteur, à trouver une autre approche pour finalement observer le résultat du déploiement plus rapidement.
L’enjeu des livraisons automatisées est double : d’abord, faciliter le transport du code vers le serveur de production (en cas de bogue, le temps passé concerne seulement la résolution du problème et non la livraison elle-même) et servir de documentation du processus de livraison.
Nous abordons plus en détail les différents mécanismes techniques dans le chapitre 6, que ce soit “à la main”, avec des recettes de déploiement ou par le biais de notre service d’hébergement.
11. Pour aller plus loin
11.1. Pourquoi lancer un serveur ?
Il y a des environnements où des logiciels comme Apache et Nginx intègrent
notre langage de programmation avec des modules : par exemple, PHP avec le mod_php
ou Perl avec le mod_cgi.
Les requêtes entrantes sont dirigées vers un script que le module interprète
et qui retourne une réponse, dynamiquement.
Le script PHP est interprété à chaque requête et toute cette représentation est détruite une fois la réponse envoyée (mémoire, valeurs des variables, configuration). Il faut recourir à un ensemble de modules additionnels pour optimiser ce gâchis de ressources informatiques : cache d’interprétation, cache applicatif, cache de configuration.
Démarrer un serveur HTTP dans le langage de notre application nous éloigne de ce modèle coûteux et nous rapproche d’un fonctionnement plus performant, organisé autour des trois piliers suivants :
-
Node et Apache/Nginx fonctionnent ensemble – ils se relaient les requêtes et les réponses car ils parlent le même protocole.
-
Le serveur Node est “préchauffé” – une requête entrante trouve une application déjà opérationnelle, déjà configurée, déjà connectée à une base de données et prête à répondre.
-
Le code exécuté est spécifique à la requête – l’application reçoit chaque requête de manière indépendante en ayant le minimum d’effort à faire pour générer une réponse.
Autrement dit, ce modèle réduit le temps de parcours entre une requête entrante et une réponse sortante. Cela a un effet significatif sur le temps d’apparition de l’icône de chargement côté client.
11.2. Comprendre le modèle HTTP
Deux éléments ressortent du modèle de fonctionnement du protocole HTTP : tout est du texte (en-têtes et contenu) et chaque requête est indépendante. Cela revient à dire que chaque requête emporte son contexte avec elle, toutes les informations nécessaires à sa compréhension.
Que se passe-t-il lorsque notre navigateur web ou le programme curl
demande à accéder à example.com ?
-
Résolution de DNS : un des annuaires DNS est interrogé pour savoir quelle adresse IP est associée au nom de domaine.
-
Établissement de la connexion : le client (nous) ouvre une connexion réseau avec le serveur pour échanger des données.
-
Envoi de la requête HTTP : la requête contient des informations au format texte (méthode, en-têtes, parfois un corps de message) pour que le serveur s’adapte au mieux à notre demande.
-
Réception de la requête : le serveur interprète la demande (est-ce qu’il la comprend ?), cherche la ressource associée au chemin demandé.
-
Envoi de la réponse : le serveur répond avec des données au format texte (statut, en-têtes, corps de message).
-
Interprétation de la réponse : l’en-tête
Content-Typeaide le client à déterminer comment afficher les informations - XML, HTML, JSON, CSS, vidéo etc – et si le document contient d’autres ressources à aller récupérer.
Dans le cas du programme curl, la réponse est affichée telle quelle, en texte.
Avec un navigateur en revanche, le HTML est interprété.
Le navigateur demande les ressources listées dans les différentes balises
(img, video, audio) ; l’indicateur de chargement
s’arrête quand toutes les ressources ont été demandées et téléchargées.
Le nombre de requêtes et la taille des ressources affectent donc la vitesse de chargement d’une page. Plus il y en a, plus le client doit en demander et plus le serveur multiplie le nombre de réponses. Le temps de téléchargement augmente.
|
💬
|
Technique Les WebViews sur mobile
Les WebViews sont des composants proposés par les systèmes d’exploitation pour embarquer du contenu HTML dans une application native. Elles fonctionnent comme des navigateurs, sans les boutons de navigation. |
Le module npm jshttp (github.com/jshttp) affiche les en-têtes
de réponse comme le programme curl le ferait et détaille le parcours réseau,
de la résolution du nom de domaine jusqu’au temps passé à négocier une transaction
sécurisée.
Nous comprenons ainsi mieux des temps qui sont rendus invisibles et sur lesquels nous
pouvons faire des efforts – réduire les temps de transfert ou le temps de réponse
de notre application par exemple.
11.3. Quel(s) moteur(s) de base(s) de données choisir ?
Quand je codais en PHP, nous parlions beaucoup de la pile technique LAMP (Linux, Apache, MySQL et PHP). C’était la combinaison de facto des différents projets. MySQL était la base de données de choix tandis que les Pythonistes et Rubyistes se focalisaient plutôt sur PostgreSQL.
J’ai croisé beaucoup de développeurs et développeuses qui se lançaient dans les bases de données dites “documents” comme MongoDB “parce que les données sont stockées en JSON et donc c’est un choix logique pour Node”.
Je suis fortement en désaccord avec cette dernière affirmation et je pense que la bonne base de données est celle qui tient la route par rapport à Node. Le débit de données entre Node et la base compte davantage, ainsi que la rapidité de la base à exécuter une requête et retourner des résultats (certaines gèrent mieux que d’autres la concurrence d’accès ou les critères de filtrage). Le troisième critère est subjectif : c’est le confort d’utilisation ; PostgreSQL est peut-être plus rapide pour un cas d’usage précis, mais si vous êtes plus à l’aise avec MariaDB ou MySQL, commencez avec la base qui vous parle le plus – ou expérimentez et réservez-vous le droit de changer d’avis après avoir joué avec un nombre représentatif de données.
Je choisis une base de données en fonction de plusieurs critères : la rapidité de lecture, l’intégrité des données, la volumétrie acceptée avant de devoir distribuer les données sur plusieurs machines et enfin, des fonctionnalités spéciales (recherche géographique, type de champ particulier comme le champ JSON de PostgreSQL).
- Stockage fichier
-
Nous pourrions tout à fait décider d’utiliser un fichier JSON ou CSV pour lire et écrire des données. C’est facile à mettre en œuvre, mais c’est la solution la plus lente à tout point de vue : recherche comme écriture.
- Stockage en mémoire
-
Redis et Memcached sont des gestionnaires très rapides en lecture et en écriture. C’est idéal pour accéder fréquemment aux données et les modifier, avant de les sauvegarder sur un stockage moins rapide mais plus sûr. Ils sont généralement dits “clé/valeur” car nous cherchons un identifiant donné pour récupérer un, voire plusieurs champ(s) associé(s).
- Stockage sur disque
-
MySQL, MSSQL, PostgreSQL et MongoDB stockent leurs données sur disque, dans des fichiers optimisés pour la recherche d’informations – les index. Ces moteurs sont souvent rapides en lecture et plus lents en écriture – selon le type de disque dur utilisé pour le stockage. Certains sont contraints par des schémas (bases SQL) tandis que d’autres ont une structure libre (MongoDB).
En pratique, nous typons ou structurons les données d’une manière ou d’une autre, a minima pour les manipuler de manière cohérente dans notre code. Certaines bases SQL ont un type de champ JSON, en structure libre. - Stockage sur un service en ligne
-
Firebase, DynamoDB, Parse et Kinto sont des gestionnaires de bases de données accessibles comme des services, avec des requêtes HTTP. Les services d’hébergement gèrent la distribution des données et leur sauvegarde.
J’utilise souvent SQLite pour prototyper quelque chose de rapide sur ma machine. Je passe ensuite à MySQL ou PostsgreSQL selon le projet – je me sens autonome sur le premier pour l’installation tandis que je préfère un service qui gère tout de bout en bout avec le second.
Je peux être amené à indexer les données dans une base Elasticsearch ou Algolia pour leur donner une autre structure, spécialement optimisée pour la recherche : une lecture très rapide sur des critères variables. Je le fais si un des aspects principaux du projet est de préserver des performances élevées, qui ne soient pas ralenties par l’activité d’une base SQL.
Je complète en général avec Redis pour gérer les files d’attente, des données intermédiaires que je considère comme “jetables”.
S’il est plus simple de tout gérer avec un seul support de stockage, utiliser plusieurs gestionnaires de bases de données dans une même application est quelque chose de tout à fait encouragé pour profiter de leurs caractéristiques.
11.4. Protéger nos applications
Il faut prendre des mesures de précaution dès lors que nous utilisons des données saisies par un utilisateur, c’est-à-dire toute variable dont la valeur provient de l’extérieur. Je pense à des données de formulaire, des paramètres d’URL, des chemins d’accès, des fichiers téléversés mais aussi des scripts qui sont injectés dans la page, volontairement ou via un logiciel vérolé installé sur leur ordinateur.
- npmjs.com/helmet
-
Déjoue les injections de scripts et d’iframes non sollicitées.
- npmjs.com/safe-regex
-
Filtre une expression régulière fournie ou composée avec une valeur fournie par un utilisateur. Cela évite certains bogues qui surchargent la CPU ou qui déjouent les motifs des expressions.
- npmjs.com/dompurify
- npmjs.com/xss
-
Nettoie le HTML d’attributs et de balises non sollicités. Les injections de scripts et les événements malintentionnés de clics sont supprimés.
- npmjs.com/sql-escape-string
-
Nettoie une saisie utilisateur de tout caractère qui pourrait déjouer nos attentes au sein d’une requête SQL.
Outre les données arbitraires, il faut toujours s’assurer des permissions. L’utilisateur a-t-il vraiment le droit d’être là ou il est ? Le volume du fichier téléversé est-il vraiment cohérent ?
L’utilisation du mode strict a l’avantage de nous protéger de l’exploitation d’anciennes bizarreries d’ECMAScript. Ce qui doit planter plante au lieu d’être passé sous silence.
Parfois, même les caractères autorisés suffisent à déjouer notre attention.
C’est le cas si une variable est utilisée pour composer un chemin avec
path.resolve() ou path.join() par exemple.
La saisie utilisateur crée un chemin de traverse qui permet d’aller exploiter
des données ailleurs sur l’ordinateur.
'use strict';
const {resolve} = require('path');
const base_dir = __dirname;
const bad_user_input = '/etc/passwd';
const resolved = resolve(base_dir, bad_user_input);
console.log(resolved); // (1)
if (resolved.indexOf(base_dir) !== 0) { // (2)
console.error(`${resolved} doit commencer par ${base_dir}`);
}-
Affiche
/etc/passwd– notre chemin de base a été complètement remplacé. -
Affiche
/.../chapter-07/examples– notre chemin de base a été complètement remplacé.
Un moyen solide de vérifier que nous n’avons pas été dérouté·e en dehors
d’un répertoire racine – ici, base_dir – est de vérifier que le chemin final
débute bien par le chemin du répertoire racine.
| En-tête | Description |
|---|---|
|
Avec la valeur |
|
Avec la valeur |
|
Lorsque l’option est activée, le navigateur accède par défaut à ce site en HTTPS au lieu de HTTP. |
|
Avec la valeur |
|
Avec la valeur |
|
Avec la valeur |
|
💡
|
Guide Open Web Application Security Project (OWASP)
L’organisme Open Web Application Security Project (OWASP) recueille et diffuse nombre de critères de sécurité à connaître et vérifier pour déjouer au mieux les attaques. Il met à disposition un guide spécialisé pour Node à l’adresse suivante : |
11.5. Une application minimaliste avec les Lambda
Le principe d’une application web est d’afficher un résultat à partir d’un chemin d’accès et de rester allumée en permanence, sauf exception. Les Lambda sont une approche minimaliste d’application web : il n’y a qu’une seule route, c’est une seule fonction qui retourne un résultat.
L’application s’endort quand elle ne reçoit pas de trafic dans un laps de temps donné. Elle est “réveillée” quand du trafic arrive. La facturation se fait à l’échelle de la seconde et au nombre de requêtes entrantes. Nous en parlons un peu plus en détails dans le chapitre 6.
Ce mécanisme s’adapte à des résultats en réaction à un événement : webhook, notification, erreur, etc.
Le module npm micro (npmjs.com/micro) est un serveur minimaliste
qui répond à ce principe de micro-application, prête à être mise en pause à
tout instant.
'use strict';
const micro = require('micro');
const {random} = require('pokemon');
const server = micro((req, res) => random()); // (1)
server.listen(4000); // (2)-
Nous avons accès à la requête et à la réponse, mais nous avons aussi la liberté de renvoyer un résultat à la fonction de rappel.
-
À la manière d’une application classique, nous la démarrons sur le port HTTP de notre choix.
Un service comme AWS Lambda (aws.amazon.com/lambda) pousse le concept encore plus loin. La fonction réagit à un événement interne (notification SQS, quelque chose lié à notre infrastructure, déploiement) ou à un événement externe (via l’API ou un autre service ouvert vers l’extérieur). Elle n’est pas forcément exposée sur le Web.
'use strict';
const lambda = require('apex.js');
const {random} = require('pokemon');
module.exports = lambda(event => random()); // (1)-
C’est tout ce qu’il faut pour qu’une Lambda retourne un résultat utilisable pour l’appelant.
L’adaptabilité de ce mécanisme permet de créer une API complète en agrégeant plusieurs Lambda derrière un portail d’API comme AWS API Gateway (aws.amazon.com/api-gateway). À une API et une ressource (chemin et méthode HTTP) est associée une ressource AWS, dont les Lambda font partie.
12. Conclusion
Nous avons vu qu’une application web est bâtie autour du protocole HTTP. Elle passe son temps à interpréter le texte des requêtes entrantes et à produire des réponses, elles aussi au format texte. Ces données de sortie sont aussi bien issues des fichiers placés sur notre disque que des pages HTML assemblées dynamiquement depuis une base de données.
Les frameworks structurent notre pensée et automatisent l’application de vérifications et de transformations pour toutes les requêtes entrantes. Une fois le concept maîtrisé, il devient plus facile d’en essayer de nouveaux et d’utiliser celui qui nous plaît le plus.
Nous avons aussi constaté qu’une approche modulaire permet d’interchanger des modules entre eux, mais aussi qu’elle amène naturellement à une structure adaptée aux frameworks et à l’écriture de tests, indispensables pour améliorer la confiance dans notre code et pour en automatiser les déploiements.
Le protocole HTTP est une pierre angulaire du Web tel que nous l’utilisons. Le pratiquer avec Node est un bon moyen de le comprendre par la pratique.