|
💡
|
Vous êtes en train de lire le Chapitre 6 du livre “Node.js”, écrit par Thomas Parisot et publié aux Éditions Eyrolles. L’ouvrage vous plaît ? Achetez-le sur Amazon.fr ou en librairie. Donnez quelques euros pour contribuer à sa gratuité en ligne. |
En déployant une application Node, nous améliorerons la qualité de notre code en gommant les derniers bogues et en automatisant la détection des erreurs et des failles de sécurité.
-
Déployer une application Node
-
Choisir son hébergement
-
Améliorer la portabilité
-
Démarrer automatiquement nos applications
-
À quoi penser après la mise en ligne ?
Ce chapitre nous permettra d’y voir plus clair du côté de l’hébergement et de la mise en ligne d’une application Node. Nous pourrons choisir ce qui nous paraît le plus abordable, que ça soit en termes d’argent ou de complexité d’utilisation.
Nous mettrons en œuvre les variables d’environnement du chapitre 4 pour que nos applications en ligne fonctionnent de la même manière que sur notre ordinateur.
Enfin, nous verrons différents types de service pour être tenu·e informé·e des erreurs applicatives et des failles de sécurité, sans effort.
|
💬
|
Remarque Versions de Node et npm
Le contenu de ce chapitre utilise les versions Node v10 et npm v6. Ce sont les versions stables recommandées en 2022. |
|
💡
|
Pratique Jouer avec les exemples dans un terminal
Les exemples titrés d’un nom de fichier peuvent être installés sur votre ordinateur. Exécutez-les dans un terminal et amusez-vous à les modifier en parallèle de votre lecture pour voir ce qui change. Installation des exemples via le module npm
nodebooknpm install --global nodebook nodebook install chapter-06 cd $(nodebook dir chapter-06) La commande suivante devrait afficher un résultat qui confirme que vous êtes au bon endroit : node hello.js Suivez à nouveau les instructions d’installation pour rétablir les exemples dans leur état initial. |
7. Déployer une application Node
Le choix de la technique de déploiement dépend de plusieurs facteurs qui renvoient à eux-mêmes : l’hébergement peut dépendre du déploiement et vice-versa.
Je vous propose de partir balayer les différentes techniques de déploiement avec des exemples et de voir quelles seraient les raisons d’opter pour l’une ou l’autre d’entre elles.
Le choix est subjectif et vous appartient, en fonction de votre aisance à vous en emparer. C’est un sujet qui prend du temps avant d’être maîtrisé, donc n’hésitez pas à vous y reprendre à plusieurs fois.
| PaaS | Mutualisé | Cloud | Lambda | |
|---|---|---|---|---|
✘ |
✘ |
✘ |
✘ |
|
✘ |
✔ |
≈ |
✘ |
|
✔ |
✘ |
✘ |
✘ |
|
✔ |
✘ |
✔ |
✔ |
|
✔ |
✘ |
✔ |
✘ |
|
✔ |
✔ |
✔ |
✘ |
|
✔ |
✔ |
✔ |
✔ |
|
✔ |
✘ |
✔ |
✘ |
|
✔ |
✔ |
✔ |
✔ |
7.1. En codant dans un navigateur web
Le moyen le plus rapide d’exécuter un programme Node sans avoir à se préoccuper du déploiement est d’utiliser un service en ligne et de modifier le code avec un navigateur web.
Je recommande RunKit (runkit.com) pour créer rapidement
du code qui tient dans un seul fichier, sans installer Node sur sa machine.
Le code est exécuté sur les serveurs de RunKit, le résultat s’affiche chez nous.
Les modules npm
(chapitre 5) sont installés automatiquement dans
leur version la plus récente.
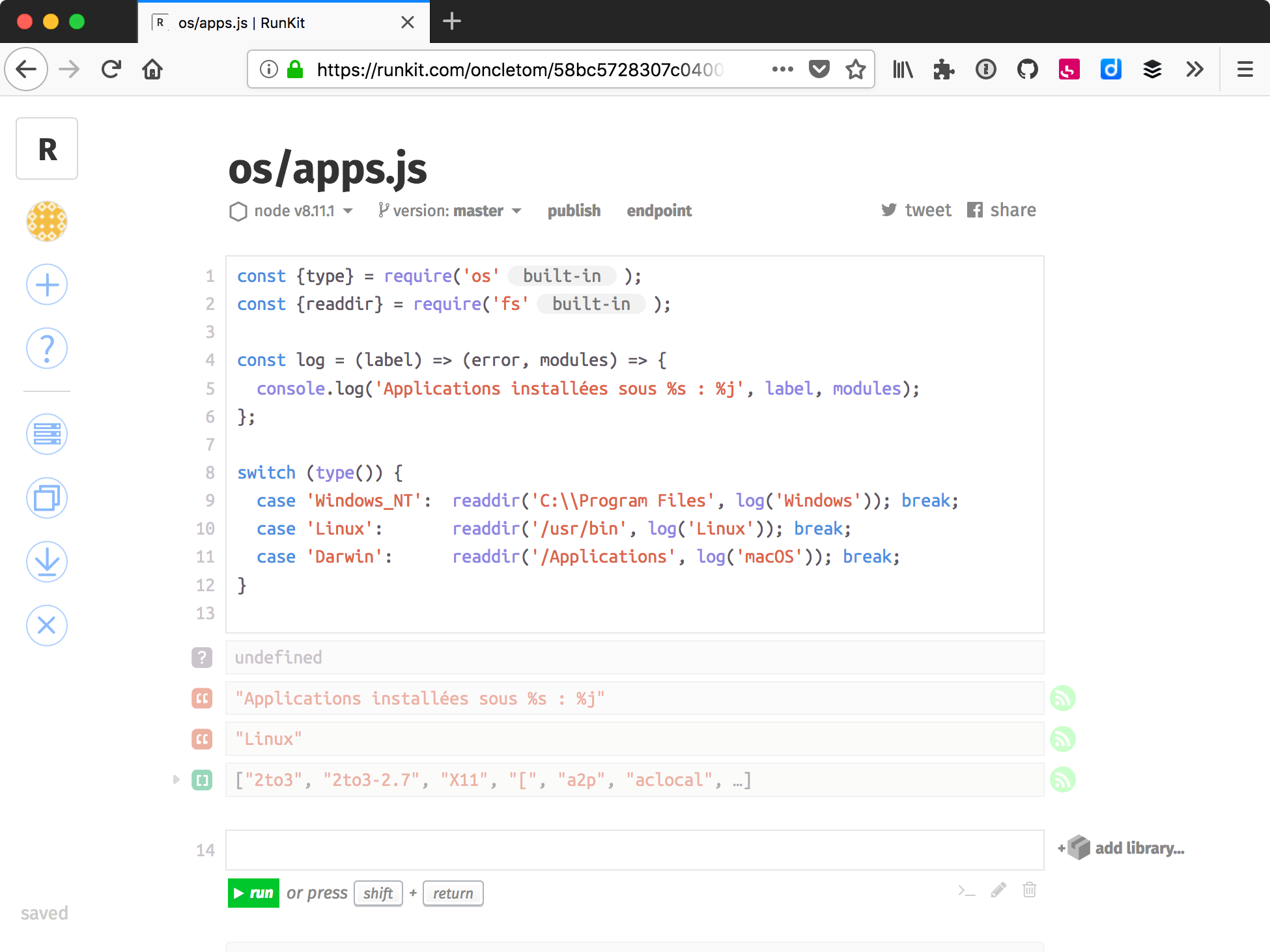
RunKit propose aussi un modèle de fonction éphémère dont le résultat devient accessible depuis une URL dédiée. Essayez de copier/coller le code suivant dans un nouveau notebook en vous rendant sur runkit.com/new :
'use strict';
const pokemon = require('pokemon-random-name'); // (1)
exports.endpoint = (request, response) => { // (2)
response.end(pokemon());
};-
Le module npm npmjs.com/pokemon-random-name exporte une fonction qui retourne un nom aléatoire de Pokémon.
-
exports.endpointest spécifique à RunKit et accepte une fonction identique à l’événementserver.on('request')du modulehttp(chapitre 4).
Une fois sauvegardé puis cliqué sur le lien endpoint,
un nouvel onglet s’ouvre et affiche un nom aléatoire de Pokémon.
C’est la valeur de retour passée à la réponse, comme on l’aurait fait
avec le module http ou dans une
application web (chapitre 7).
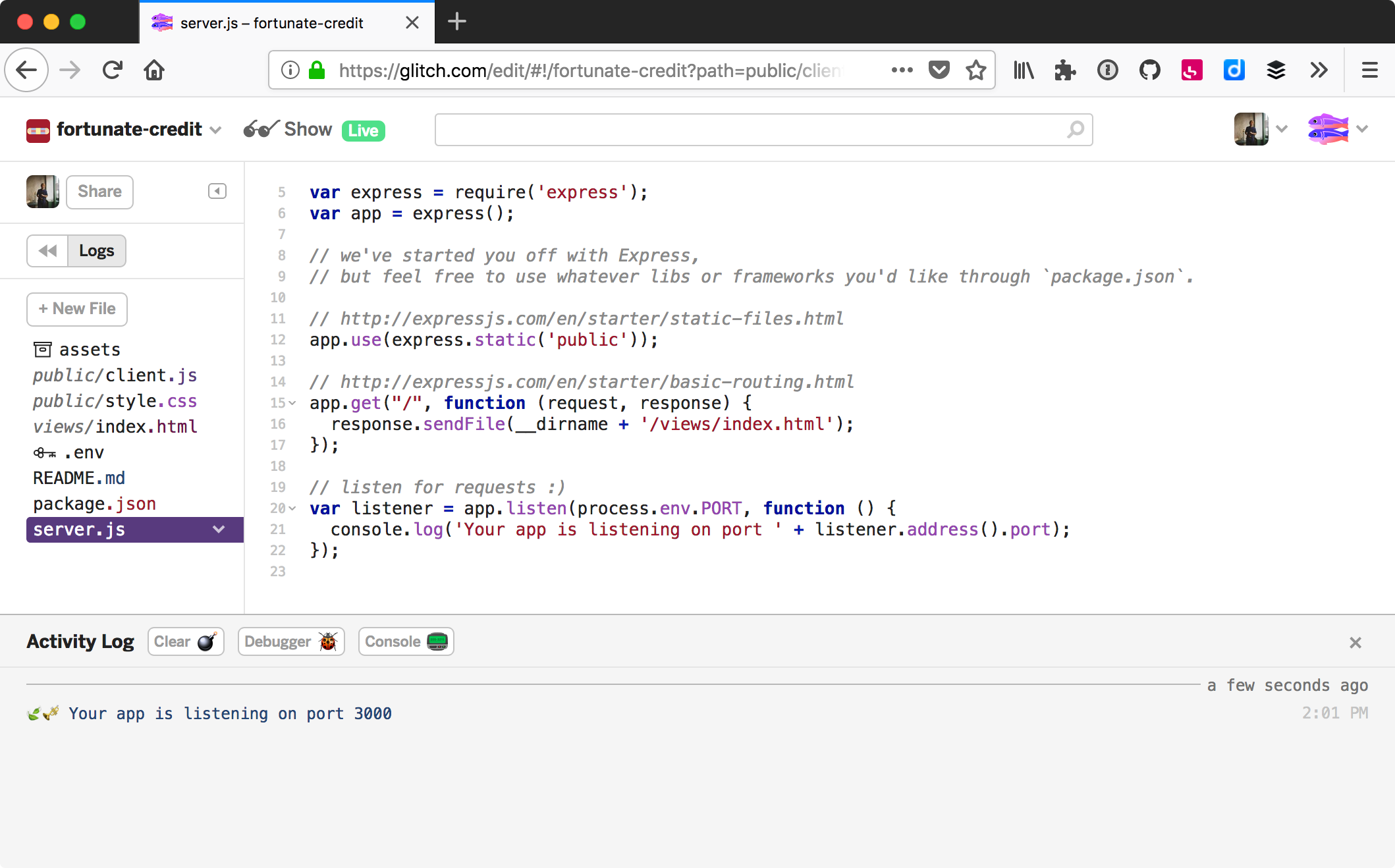
Le service en ligne Glitch (glitch.com) va plus loin
en développant, hébergeant et partageant des applications complètes.
Le service redéploie notre application à chaque changement.
Le fichier .env stocke les
variables d’environnement de manière
sécurisée – personne d’autre que nous n’y a accès.
|
💡
|
Pratique Console web
Glitch nous offre même une console web : un terminal entièrement fonctionnel, depuis un navigateur ! C’est parfait pour coder un outil en ligne de commande (chapitre 8) en travaillant depuis plusieurs ordinateurs sans avoir à tout réinstaller à chaque fois. |
|
💡
|
Pratique Remixez les exemples de cet ouvrage
Vous pouvez créer votre premier projet sur Glitch. Remixez cet ouvrage en vous rendant sur https://glitch.com/edit/#!/remix/nodebook. Le contenu et les exemples seront copiés dans un nouveau projet, exécutable et modifiable selon vos envies. |
7.2. En transférant des fichiers via SSH
Transférer des fichiers est idéal pour débuter et lorsqu’on n’utilise pas Git pour versionner son code.
Les services d’hébergement mutualisé, virtualisé ou dédié accordent un accès à votre espace en ligne par le biais de SSH (fr.wikipedia.org/wiki/Secure_Shell). Ce protocole crée une connexion sécurisée : les commandes saisies dans votre terminal font effet sur la machine sur laquelle vous êtes connecté·e.
Des logiciels comme FileZilla Client (filezilla-project.org/) servent d’interfaces graphiques pour transférer des fichiers vers une machine distante.
Les codes d’accès SSH se trouvent en général dans la section Aide ou Guides de votre hébergeur.
|
💡
|
Windows WinSCP
WinSCP (winscp.net) est une alternative libre à FileZilla pour Windows. |
|
💬
|
Avancé scp et rsync
Notre terminal peut aussi servir à transférer des fichiers. Deux programmes se basent sur SSH et sont installés par défaut sur la plupart des ordinateurs Linux et macOS :
|
7.3. En important du code depuis GitHub
Importer du code depuis GitHub est la manière la plus simple de transférer tous les fichiers versionnés sans être familier avec Git.
La plate-forme de programmation en ligne Glitch offre une option pour importer n’importe quel projet GitHub – à partir du moment où le dépôt est public.
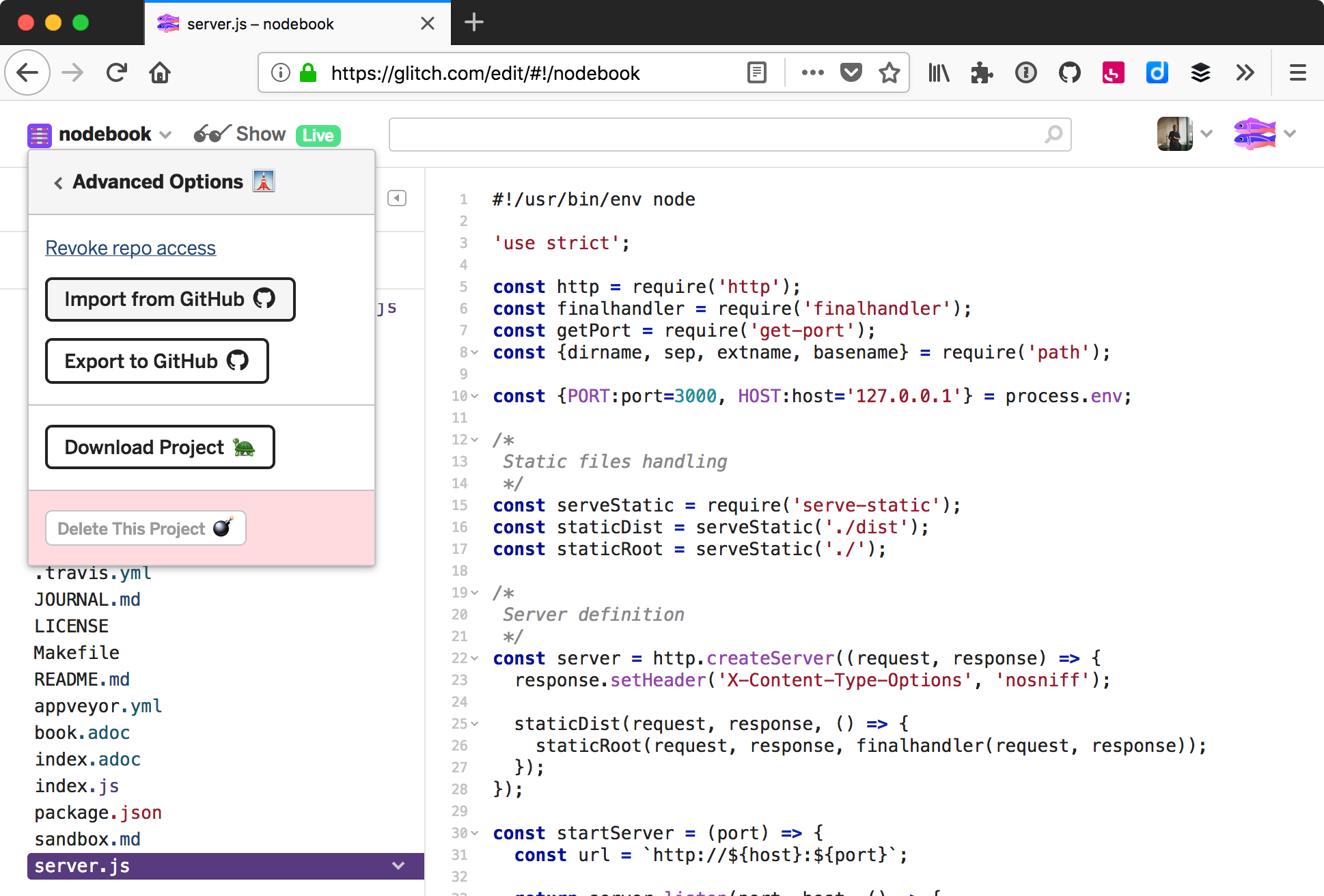
Un clic sur le bouton Import from GitHub ouvre une invite de saisie destinée à mentionner le nom du dépôt GitHub concerné. Le projet en cours sera entièrement remplacé par le contenu du dépôt distant. C’est pratique pour récupérer des exercices ou pour apprendre en travaillant sur du code écrit par quelqu’un d’autre.
|
💡
|
Pratique Importer les exemples de cet ouvrage
Récupérez tout le contenu et les exemples de cet ouvrage
en recopiant |
La plate-forme de services Heroku (heroku.com) pousse l’import GitHub un peu plus loin. Sa fonctionnalité déploie l’application à chaque nouveau commit. L’application redémarre ensuite automatiquement pour prendre les changements en compte.
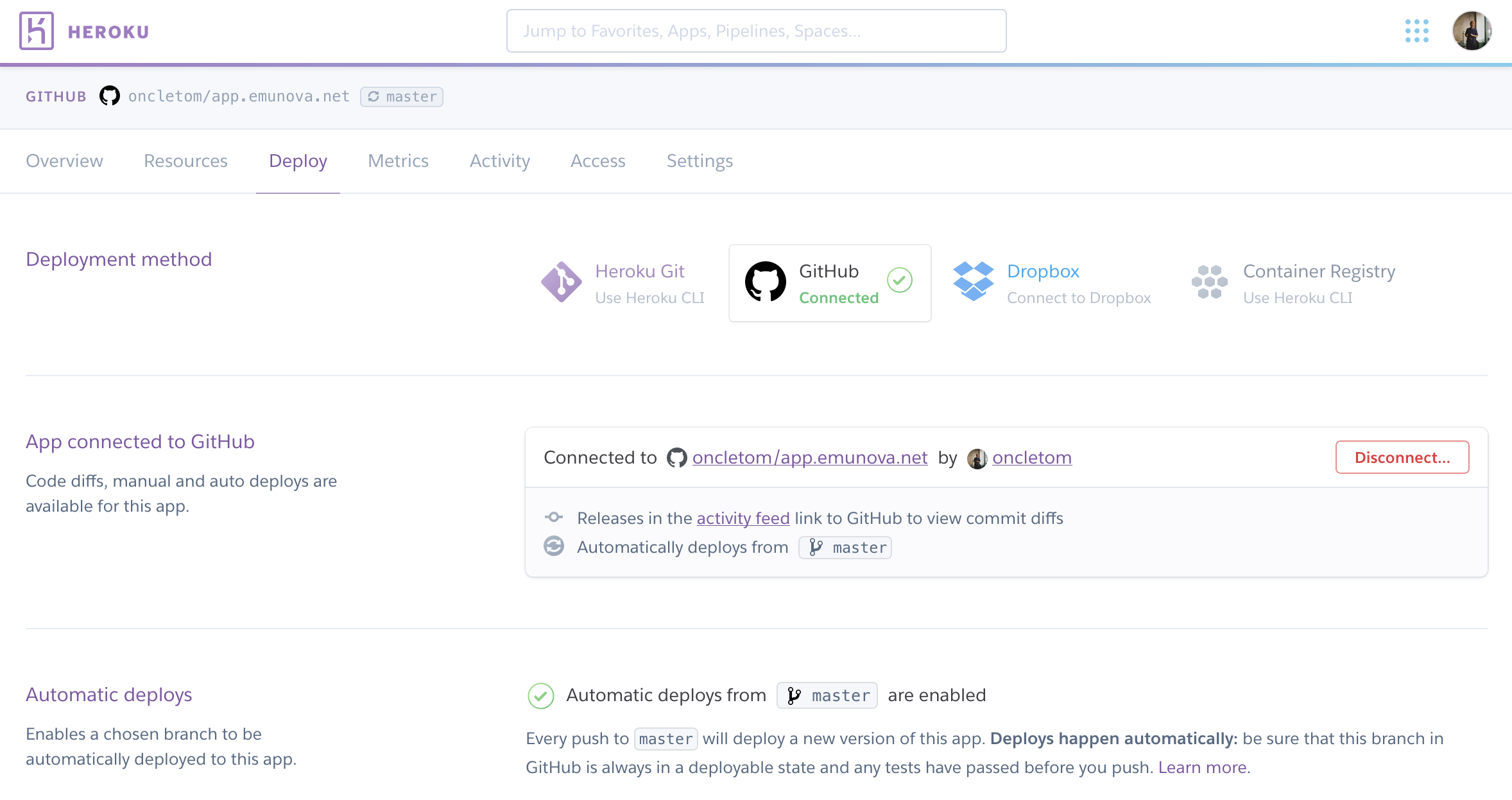
Une option nous permet de déployer une nouvelle version de l’application à la suite d’une intégration continue réussie. Nous réduisons ainsi les risques de déployer une version défectueuse.
7.4. Avec l’outil en ligne de commande de l’hébergeur
L’outil en ligne de commande d’un hébergeur permet de gérer les déploiements et d’autres aspects de l’hébergement en même temps.
La plate-forme de services now (zeit.co/now) est un exemple de simplicité à ce niveau.
npm install -g now now login
Dans un terminal, déplacez-vous vers le répertoire de l’application à déployer.
Il suffit de taper now pour transférer les fichiers.
Les dépendances s’installent et le déploiement est accessible quelques secondes
plus tard :
now Deploying ~/workspace/dtc-innovation/food-coops-dashboards Using Node.js 9.10.1 (requested: `>=8.0.0`) https://food-coops-dashboards-okgwzegyus.now.sh Synced 1 file (169.84KB) [11s] Building... ▲ npm install ✓ Using "package-lock.json" ⧗ Installing 9 main dependencies... ▲ npm install added 389 packages in 8.609s ▲ Snapshotting deployment Build completed Verifying instantiation in bru1 ✔ Scaled 1 instance in bru1 [31s] Success! Deployment ready
En optant pour l’offre payante, nous pouvons aussi gérer les noms de domaine et sous-domaines en leur attribuant l’URL du déploiement :
now alias food-coops-dashboards-okgwzegyus.now.sh my-domain.com
|
💬
|
Pratique Application de bureau
Le client en ligne de commande existe en version graphique. Un glisser/déposer de fichiers suffit à lancer un déploiement. Il se télécharge sur zeit.co/download. |
L’outil de la plate-forme de services Heroku suit une approche légèrement différente. Il nous informe de l’état de nos applications et en augmente ou diminue la quantité de ressources allouée à leur fonctionnement. Il simplifie la configuration de Git et délègue le déploiement à ce dernier. L’outil se télécharge sur devcenter.heroku.com/articles/heroku-cli.
herokuheroku login
La commande heroku apps:create crée une nouvelle application chez Heroku.
On peut faire la même chose dans un navigateur web en nous rendant sur
dashboard.heroku.com/new-app.
La commande heroku git:remote associe notre copie locale Git à cette application :
heroku apps:create --region eu Creating app... done, ⬢ polar-taiga-61296, region is eu https://polar-taiga-61296.herokuapp.com/ https://git.heroku.com/polar-taiga-61296.git heroku git:remote --app polar-taiga-61296
Il ne nous reste plus qu’à pousser notre code avec Git pour terminer la mise en ligne.
7.5. En faisant git push depuis sa machine
Le déploiement d’une branche Git est le moyen le plus facile d’automatiser tous les aspects d’un déploiement.
Cette méthode est privilégiée par les plates-formes de services comme Heroku, now et Clever Cloud. Chaque projet d’application est accessible via un dépôt Git distant (remote) : un dépôt est utilisé pour versionner notre code (GitHub par exemple) tandis qu’un autre sert pour réceptionner le code à déployer.
L’exemple suivant part du principe que notre terminal est positionné dans un répertoire qui est un projet Git contenant au moins un commit. Vous avez déjà configuré le dépôt distant à l’aide de l'outil de déploiement Heroku (section précédente).
Nous pouvons vérifier si le dépôt est bien configuré à l’aide de la
commande git remote :
git remote -v heroku https://git.heroku.com/mon-application.git (fetch) heroku https://git.heroku.com/mon-application.git (push) origin git@github.com:mon-compte/mon-application.git (fetch) origin git@github.com:mon-compte/mon-application.git (push)
La commande heroku git:remote crée un remote nommé
heroku.
Heroku redéploie notre application dès qu’on lui envoie du code avec
git push heroku :
git push heroku Counting objects: 4, done. Delta compression using up to 4 threads. Compressing objects: 100% (4/4), done. Writing objects: 100% (4/4), 17.77 KiB | 5.92 MiB/s, done. Total 4 (delta 2), reused 0 (delta 0) remote: Compressing source files... done. remote: Building source: remote: remote: -----> Node.js app detected remote: remote: -----> Creating runtime environment ... remote: -----> Launching... remote: Released v30 // (1) remote: https://mon-application.herokuapp.com/ deployed remote: remote: Verifying deploy... done.
-
C’est le trentième déploiement – on peut revenir à une version antérieure si nécessaire.
L’URL de l’application est rappelée dans les logs du déploiement. En cas d’erreur, la version précédente de l’application reste en ligne. Nous avons ainsi le temps de corriger le problème sans interruption de service.
7.6. En faisant git pull lors d’une session SSH
La récupération du code source à distance avec Git et SSH est une manière de déployer similaire à la mise à jour et au démarrage d’une application sur notre ordinateur.
Cette technique s’applique si notre application est placée sur un hébergement mutualisé, dédié ou virtualisé ou une offre cloud.
L’exemple suivant illustre l’initialisation d’un projet via la connexion SSH à un hébergement mutualisé chez alwaysdata.
ssh moncompte@ssh-moncompte.alwaysdata.net git clone https://github.com/moncompte/monprojet . npm install
Nous avons cloné un projet comme nous aurions pu le faire si nous installions notre projet depuis zéro sur notre ordinateur.
Dans le cas d’une mise à jour, nous récupérons les changements depuis le dépôt
distant avec git pull.
npm install met à jour les dépendances s’il y a des différences entre
le contenu du fichier package.json et les modules déjà installés
(chapitre 5).
ssh moncompte@ssh-moncompte.alwaysdata.net git pull npm install
Dans le cas d’alwaysdata, l’application se redémarre depuis l'interface d’administration. Dans les autres cas, redémarrez l’application selon le procédé choisi après avoir lu la section “Démarrer automatiquement nos applications”.
7.7. Avec une recette de déploiement (Ansible, Chef, etc.)
La recette de déploiement est la manière la plus complète de partager et d’automatiser un déploiement complexe.
Cette méthode se place dans la continuité de
git pull lors d’une session SSH : nous orchestrons les
actions nécessaires au déploiement en les listant dans un
fichier de configuration, en choisissant dans quel ordre les déclencher
et sur quel(s) serveur(s).
Nous retrouvons Puppet (puppet.com), Chef (www.chef.io) et Ansible (ansible.com) parmi les outils les plus utilisés et les mieux documentés. Ils ont des philosophies de configuration et d’exécution différentes – l’idéal est encore d’essayer d’écrire une première recette avec chacun d’entre eux pour voir celui qui vous semble le plus naturel à utiliser.
Ma préférence va vers Ansible car le logiciel s’installe facilement sur macOS et Linux, se configure avec une syntaxe que je connais déjà (YAML) et je trouve ses messages d’erreurs informatifs.
L’exemple suivant illustre le déploiement de l’application Node Slackin (github.com/rauchg/slackin) sur l'hébergement mutualisé alwaysdata :
ansible-playbook -i ansible/inventory.yaml ansible/playbook.yaml PLAY [webservers] ******************************* TASK [Gathering Facts] ************************** ok: [ssh-moncompte.alwaysdata.net] TASK [code source via git] ********************** ok: [ssh-moncompte.alwaysdata.net] TASK [mise à jour des modules `npm`] ************** ok: [ssh-moncompte.alwaysdata.net] PLAY RECAP ************************************** ssh-moncompte.alwaysdata.net : ok=3
La commande précédente a eu pour effet de créer des connexions SSH avec les
machines listées dans le fichier inventory.yaml puis de jouer les actions
listées dans le fichier playbook.yaml.
|
💬
|
Inventaire
Liste de serveurs connus sur lesquels effectuer des déploiements. En les catégorisant (par type, par emplacement), on contrôle finement les actions à déclencher ; par exemple, uniquement les serveurs web de production, les bases de données de test, l’API de la région Europe. |
|
💬
|
Playbook
Liste des actions possibles en fonction des types de serveurs. Ces actions peuvent être rejouées à l’infini et de manière prédictible. |
Le playbook suivant illustre deux tâches appliquées uniquement sur
les serveurs étiquetés dans notre inventaire en tant que webservers :
---
- hosts: webservers
tasks:
- name: code source via git
git: // (1)
repo: "https://github.com/rauchg/slackin.git" // (2)
dest: "{{ ansible_env.HOME }}"
clone: yes // (3)
update: yes // (4)
- name: mise à jour des modules npm
npm: // (5)
state: present // (6)
path: "{{ ansible_env.HOME }}"
production: true // (7)-
Actions Git – docs.ansible.com/ansible/2.5/modules/git_module.
-
Adresse du dépôt Git à récupérer.
-
Indique de cloner le dépôt s’il n’est pas déjà présent.
-
Indique de récupérer les commit du dépôt en faisant
git pull. -
Actions npm – docs.ansible.com/ansible/2.5/modules/npm_module.
-
Indique d’installer les dépendances
npmavecnpm install. -
Indique de lancer la mise à jour des modules
npmavec l’option--production– c’est-à-dire sans les dépendances listées dans le champdevDependencies.
Les tâches sont réplicables sur les serveurs listés dans un fichier d’inventaire.
webservers:
hosts:
ssh-moncompte.alwaysdata.netNous déployons sur un seul serveur dans ce cas de figure, mais nous pourrions tout à fait déployer une même application avec la même configuration sur une dizaine de serveurs (application à fort trafic) ou chez plusieurs centaines de clients. Dans tous les cas, l’application serait dans un état cohérent sur toutes les machines, avec peu de chances d’oublier une opération et une plus grande facilité à revenir en arrière.
7.8. En publiant une image Docker
Une image Docker est un moyen fiable de reproduire le même environnement applicatif et ses dépendances sur plusieurs systèmes d’exploitation (Windows, Linux, macOS).
Un des objectifs de Node est de faire fonctionner un même script sur tout système d’exploitation compatible. Docker (www.docker.com) pousse cette compatibilité plus loin en empaquetant tout ce qui est nécessaire au bon fonctionnement de l’application (dépendances, logiciels système). Le mécanisme d’exécution aide à la fois à orchestrer plusieurs conteneurs entre eux – y compris bases de données et moteurs de recherche – et à revenir dans l’état applicatif initial.
Le fichier suivant est un exemple fonctionnel d’image Docker.
Son intention est de créer un environnement Node v10
pour une application web (chapitre 7)
qui comporte une dépendance npm (chapitre 5) :
FROM node:10-alpine
WORKDIR /app
COPY ./app.js ./app.js
COPY ./package.json ./package.json
RUN npm install --production
EXPOSE 4000
CMD ["npm", "start"]Nous choisissons l’environnement Node (FROM), avant de procéder à la copie
des fichiers applicatifs vers l’image (COPY).
Suite à cela, nous installons aussi les dépendances de l’application et spécifions
quelle commande effectuer lorsque l’image Docker est lancée (CMD).
L’image se construit et on démarre le conteneur sur notre ordinateur comme suit :
docker build -t nodebook/demo . docker run -ti --rm -p 4000:4000 nodebook/demo curl -L http://localhost:4000
Nous avons déjà parlé de l'outil en ligne de commande
du service now (zeit.co/now) dans la section du même nom.
Il est aussi capable de déployer un conteneur Docker en se basant sur un fichier
Dockerfile en ajoutant l’option --docker :
now --docker --public Deploying ~/.../examples under oncletom https://examples-zlssezfiej.now.sh [in clipboard] (bru1) [7s] Synced 1 file (156B) [7s] Building… ▲ docker build Sending build context to Docker daemon 17.92 kBkB ▲ Storing image Build completed Verifying instantiation in bru1 ✔ Scaled 1 instance in bru1 [18s] Success! Deployment ready
Une autre solution consiste à publier notre image sur Docker Hub (hub.docker.com), la plate-forme officielle de partage d’images Docker, qui dispose d’une fonctionnalité de construction automatique connectée à GitHub. Docker Hub construit l’image à chaque nouveau commit, puis la met à disposition.
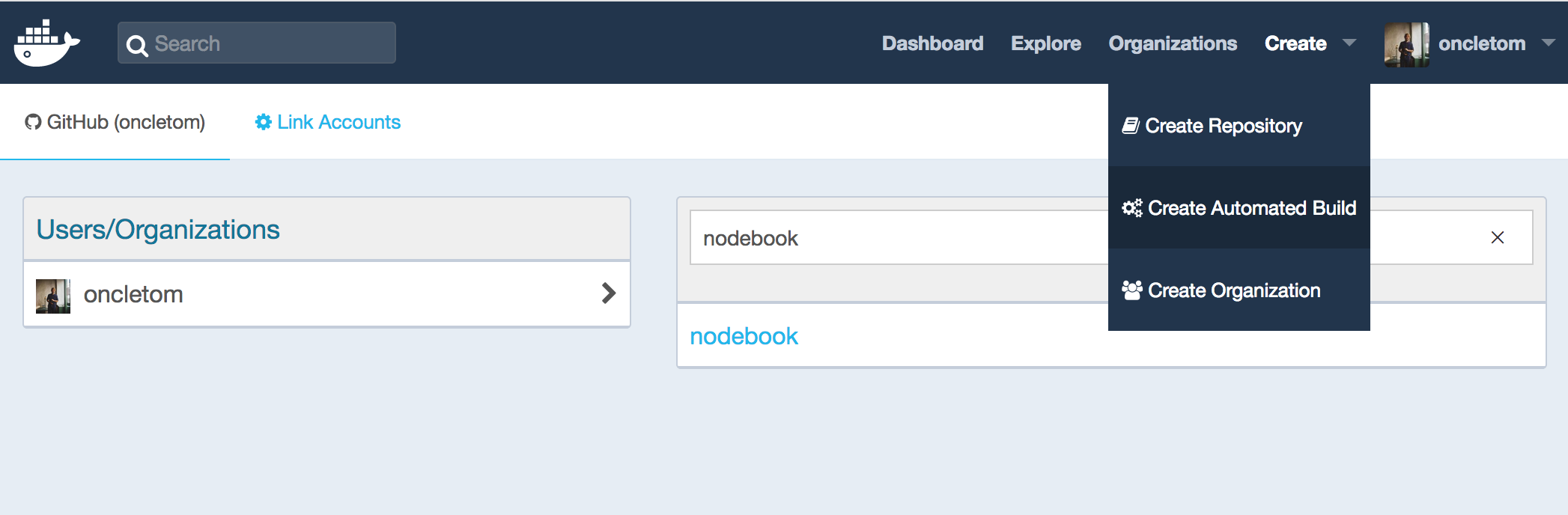
Il ne reste alors plus qu’à la collecter sur un ordinateur avec la commande
docker pull – que ce soit sur notre machine, chez notre hébergeur
ou par le biais du service d’intégration continue.
Cette façon de procéder garantit l’exécution de ce même environnement applicatif,
partout.
|
💬
|
Avancé Amazon Elastic Container Registry
Le fournisseur cloud Amazon Web Services intègre un registre privé d’images Docker pour chaque compte client. Elastic Container Registry (ECR, aws.amazon.com/ecr/) se connecte à d’autres services comme Amazon CodeDeploy pour déclencher des mises à jour d’infrastructure à chaque nouvelle image Docker. |
7.9. En paramétrant un logiciel d’intégration continue
L’utilisation d’un logiciel d’intégration continue est la manière la plus flexible d’automatiser tout type de déploiement.
L’intégration continue vise à vérifier si des régressions se sont glissées
dans notre code.
L’idée est de livrer régulièrement du code pour détecter les erreurs au plus tôt.
Les services d’intégration continue automatisent cette pratique.
Ils s’intègrent avec d’autres services pour prévisualiser les branches,
compiler la documentation mais aussi pour déployer des artefacts sur d’autres
plates-formes : registre npm,
GitHub Pages, Heroku ou même Amazon Lambda.
Le logiciel Jenkins (jenkins.io) s’installe sur notre propre infrastructure tandis que des services en ligne comme Circle CI (circleci.com), Travis CI (travis-ci.com) et CodeShip (codeship.com) mettent à disposition leur infrastructure gratuitement pour les projets open source. GitLab (www.gitlab.com) combine l’hébergement de dépôts Git et l’intégration continue.
|
💡
|
Windows Service AppVeyor
J’utilise AppVeyor (appveyor.com) en complément d’un autre service d’intégration continue quand il s’agit de tester la compatibilité du code avec Windows – ce qui est le cas des exemples de cet ouvrage. |
J’ai une préférence pour GitLab lorsque le projet y est hébergé. Le reste du temps, j’utilise Travis CI car j’aime la clarté du fichier de configuration, l’exhaustivité de la documentation et la qualité des échanges avec le service d’assistance technique.
Le fichier suivant est un exemple de configuration pour Travis CI. Il se place à la racine d’un projet à tester et s’écrit avec la syntaxe YAML :
language: node_js
node_js: {nodeCurrentVersion}
script: npm test
deploy:
provider: npm
on:
tags: true
email: "$NPM_EMAIL"
api-key: "$NPM_TOKEN"Cet exemple est structuré en trois parties :
-
configuration de l’environnement – en l’occurrence Node v10 ;
-
commande de test ;
-
configuration du déploiement en cas de succès.
Ici, le but est déployer le code sur le registre npm
quand les tests passent lors de la création d’un tag Git.
Les variables d’environnement $NPM_EMAIL et $NPM_TOKEN se règlent de
manière sécurisée sur l’écran de configuration du projet.
|
💬
|
Documentation .travis.yml
Une documentation adaptée aux projets Node est disponible à l’adresse suivante : |
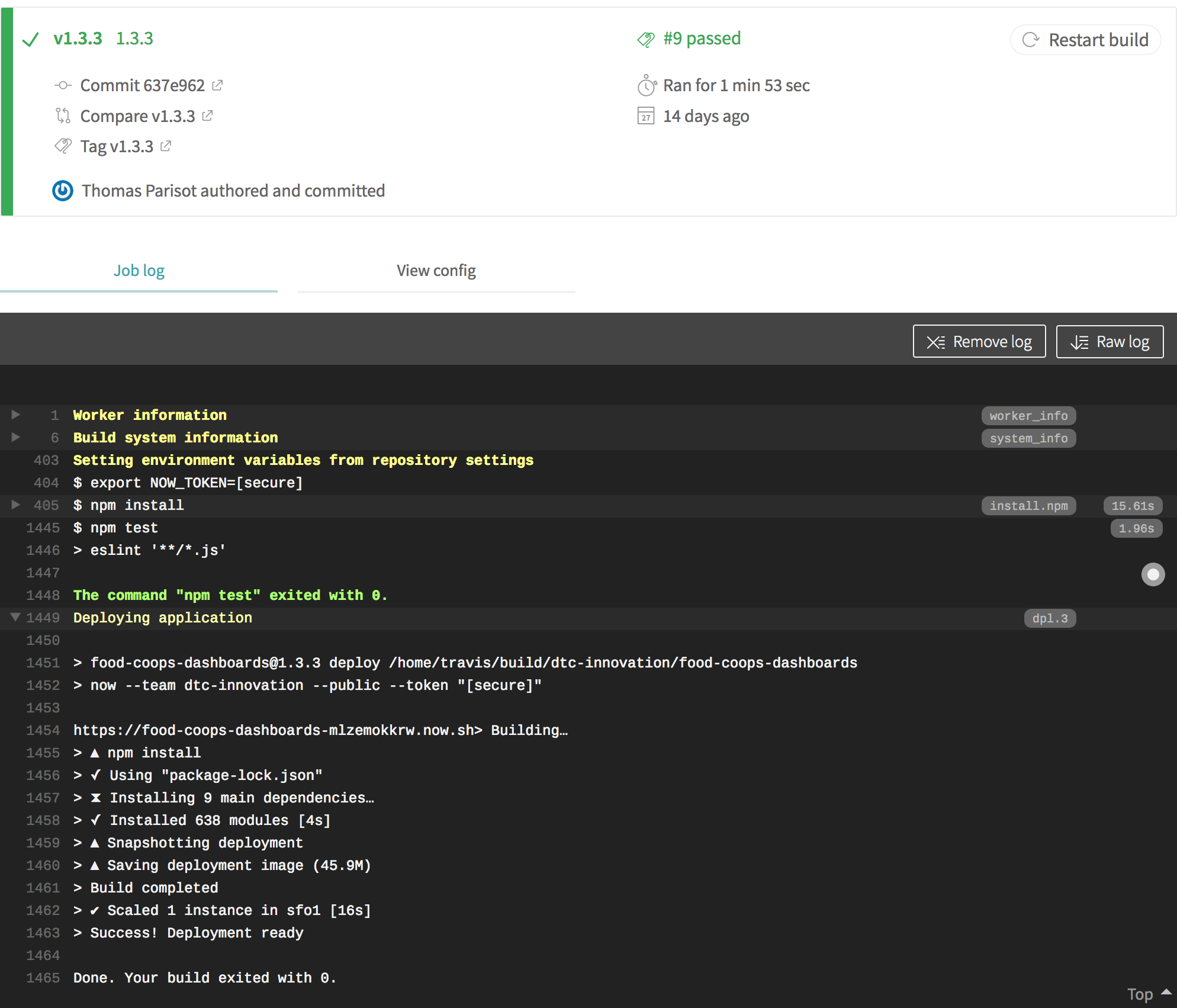
L’exemple suivant illustre l’utilisation de
l'outil en ligne de commande now dès qu’un nouveau
commit est poussé sur la branche master et que les tests passent au vert :
language: node_js
node_js: {nodeCurrentVersion}
before_deploy: npm install --global now
deploy:
provider: script
script: now --token $NOW_TOKEN
on:
branch: masterLes informations d’exécution des tests sont consignées au même titre que le statut du déploiement.
8. Choisir son hébergement
Nous allons nous intéresser aux différentes possibilités d’hébergement d’applications Node.
Côté tarifs, il en existe des gratuites sous certaines conditions, d’autres se paient à l’heure et d’autres à l’année. Certaines offres sont figées, d’autres permettent d’ajouter des machines, voire de changer la puissance en cours de route.
8.1. Plate-forme de services (Platform as a Service, PaaS)
Les plates-formes de services automatisent la configuration et le déploiement de nos applications Node, mais également Ruby, Python et PHP, entre autres. Elles se spécialisent dans des déploiements rapides, une allocation des ressources flexible, à la demande et en un clic.
C’est le moyen le plus facile de déployer une application Node, surtout si on utilise déjà Git pour versionner son code.
Leur philosophie est de tout penser en termes de ressources modulaires. On paie pour une certaine capacité de CPU et de RAM, à la minute ou à l’heure. Ces capacités s’augmentent ou se réduisent en quelques clics et sans changer une seule ligne de code dans notre application.
Une application se déploie avec un outil en ligne de commande ou
avec git push.
Et nous pouvons l’automatiser avec une recette de déploiement
et de l'intégration continue.
| Service | Déploiement | Add-ons | Gratuité | Tarif |
|---|---|---|---|---|
cli |
✘ |
3 apps |
15 $/mois/10 apps |
|
Git |
✔ |
crédit 20 € |
5 €/mois/app |
|
cli/git/SSH |
✔ |
10 jours |
5 €/mois/app |
|
Git/GitHub |
✔ |
30 jours |
7 €/mois/app |
|
cli/Git/GitHub/Dropbox |
✔ |
1 000 heures/mois |
7 $/mois/app |
La startup californienne Zeit (zeit.co) édite le service now (zeit.co/now), qui est focalisé sur l’hébergement de sites statiques, d’applications Node et de conteneurs Docker.
Sa particularité est de créer une nouvelle instance d’application par déploiement. On ne modifie donc jamais un déploiement déjà existant. On parle alors de déploiement immuable.
C’est un service que j’apprécie pour sa simplicité. C’est probablement le plus pratique à utiliser pour déployer votre première application, si vous n’utilisez pas Git ou si l’application n’utilise pas de base de données.
Heroku (heroku.com) est une autre alternative plus complète, toujours pour démarrer en douceur et sans sortir la carte bleue. Des modules optionnels couvrent nos besoins en bases de données comme MySQL, MariaDB, Redis ou PostgreSQL. D’autres services gèrent l’envoi de courriels, l’indexation de contenus, le monitoring, les logs, etc. En majorité, ils offrent un petit espace de stockage gratuit pour tester le produit.
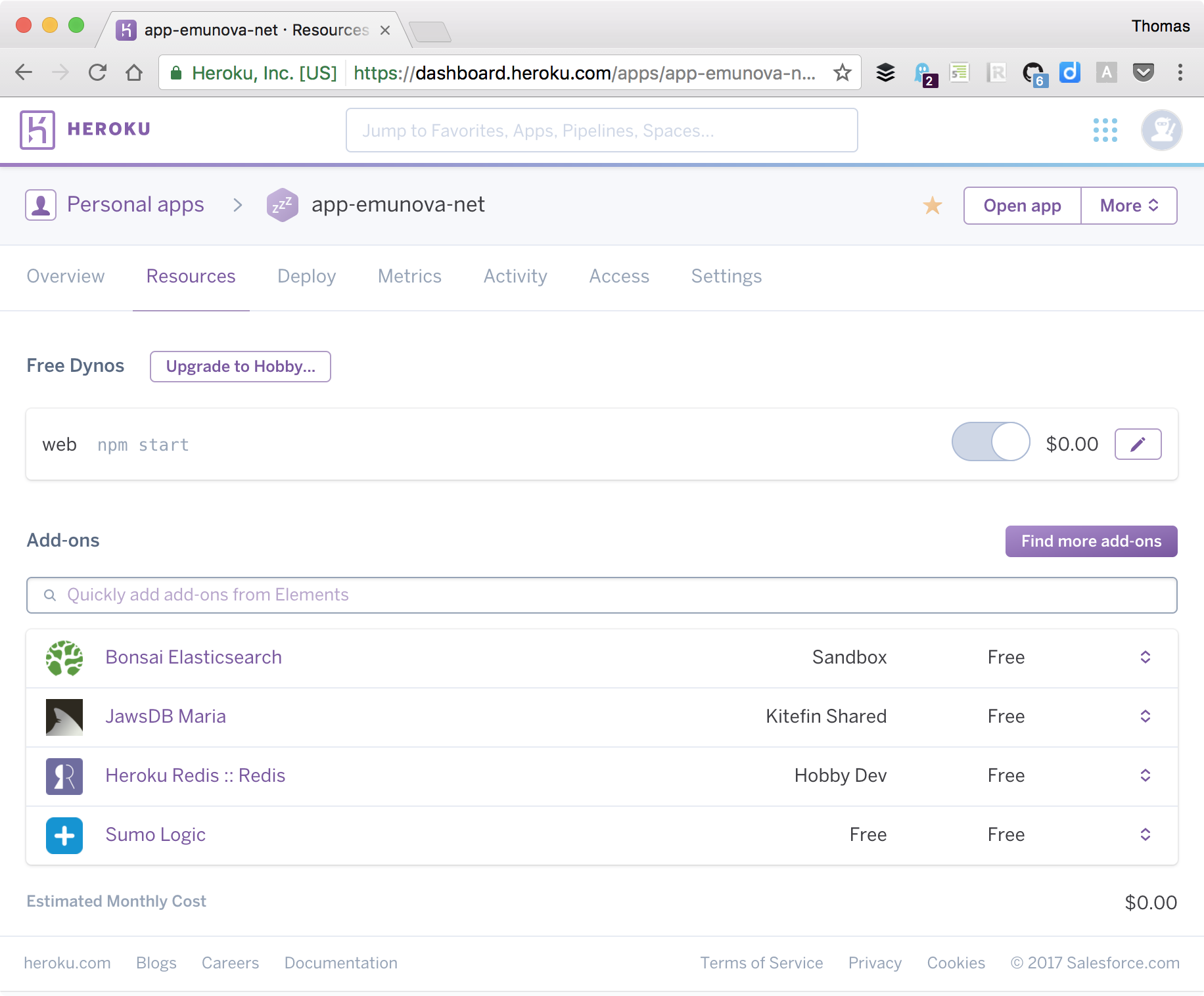
S’il est facile de déployer sur ces infrastructures et de gérer les ressources allouées à nos applications, à l’inverse la facture peut vite devenir salée à mesure qu’on augmente leur puissance. Ce coût est tout relatif : il est sûrement inférieur à celui de notre temps passé à gérer les machines si on devait tout faire à la main.
8.2. Hébergement mutualisé
Les hébergements mutualisés ont l’avantage d’être bon marché et sans entretien. Cette formule est un excellent compromis prix/services. Elle demande un peu plus d’efforts que les plates-formes de services car tout le travail d’automatisation repose sur nos épaules, si on le souhaite.
Ce modèle est adapté pour l’hébergement de fichiers statiques ou des sites web construits avec des langages de scripts comme Python ou PHP. Rares sont ceux qui ont adapté leur fonctionnement au modèle applicatif de Node.
Alwaysdata (alwaysdata.com) fait exception à la règle. Ce service d’hébergement indépendant dispose d’une formule gratuite avec 100 Mo d’espace disque pour démarrer.
Le déploiement de nos applications se fait via SSH ou SFTP, en utilisant Git, avec un service d’intégration continue ou bien en utilisant une recette.
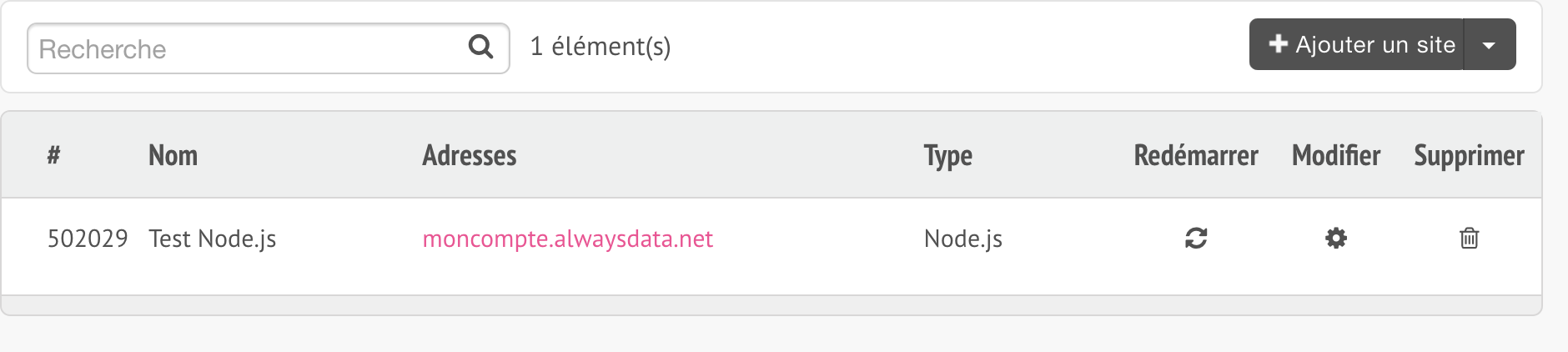
L’interface d’administration référence une section Sites dans la barre de navigation, qui liste les différents sites de notre compte. Si vous venez juste de créer le vôtre, un site a automatiquement été généré. Son URL est déterminée à partir du nom d’utilisateur que vous avez choisi lors de la phase d’inscription.
Un clic sur le bouton Modifier nous aidera à changer ses réglages :
Le nouvel écran mentionne les adresses auxquelles le site répond. En basculant vers un compte payant, on a la possibilité d’affecter un ou plusieurs domaine(s) ou sous-domaine(s) à ce même site.
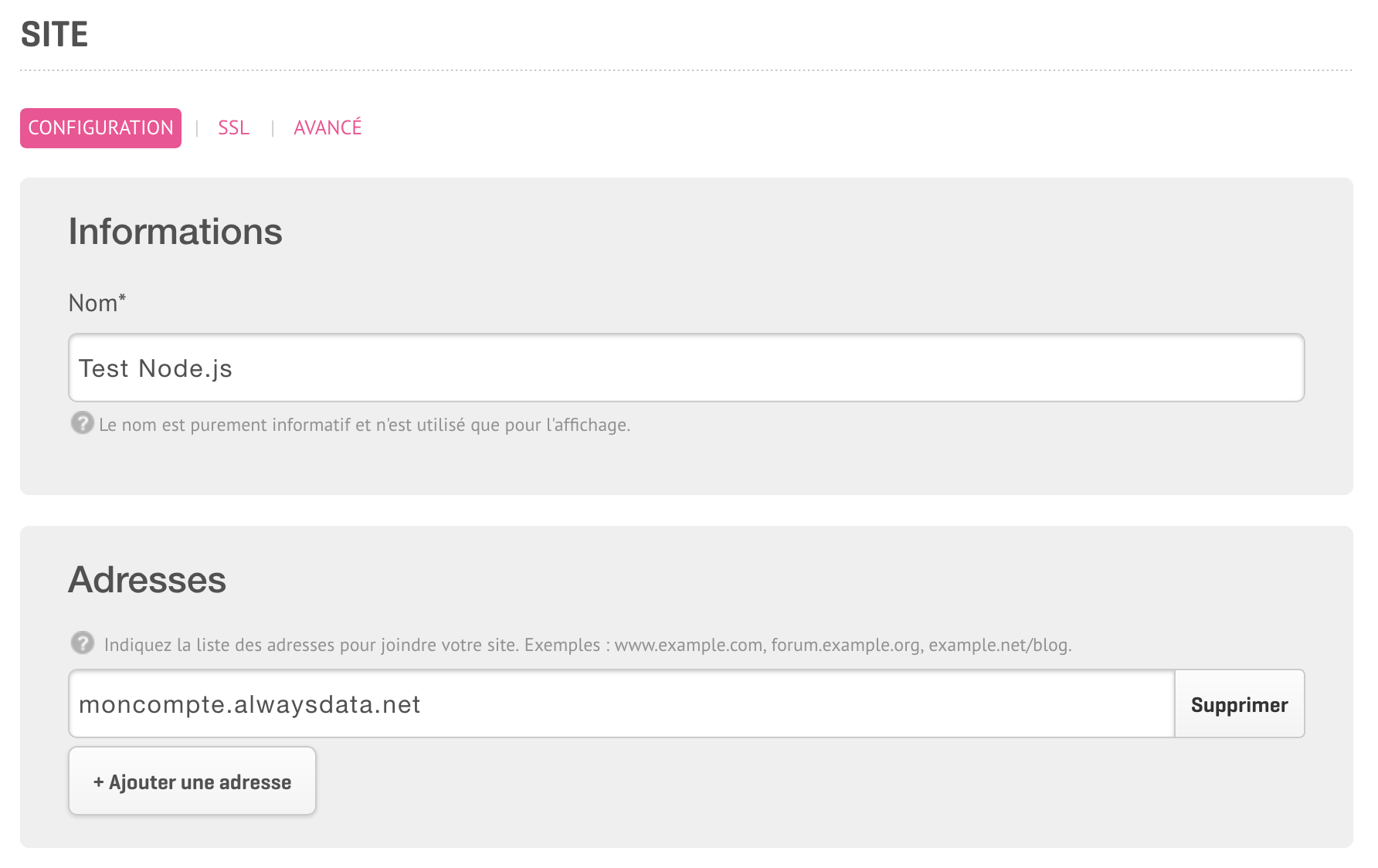
Les réglages liés à Node se trouvent sous les adresses.
Le type de site doit être changé en Node.js pour afficher
les champs de configuration qui nous intéressent.
La commande se configure de la même manière
que l'exécution d’un script Node
(chapitre 4).
On peut aussi faire appel au
script npm start comme vu
au chapitre 5 :
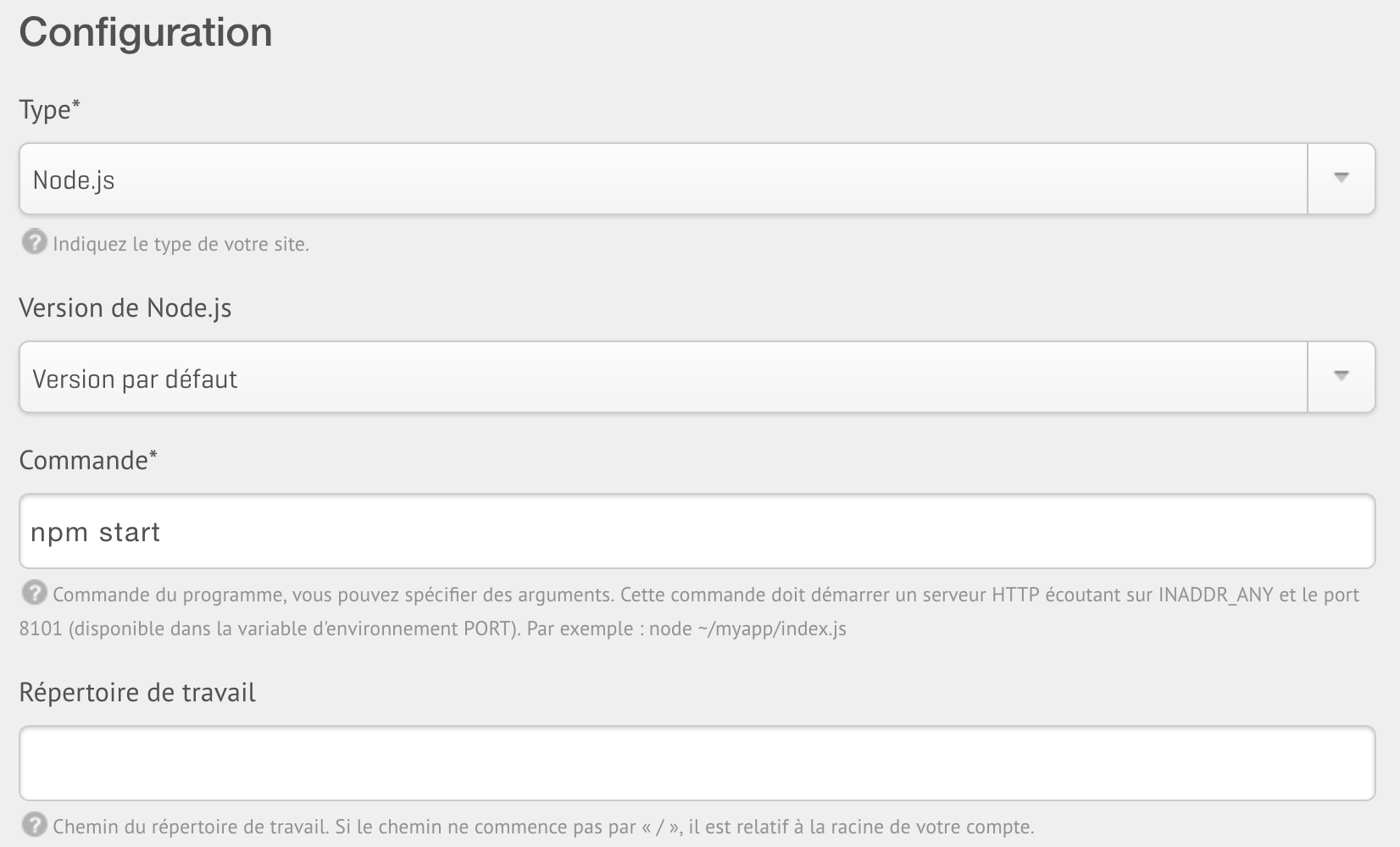
La commande complète devrait apparaître dans la section Processus une fois la configuration sauvegardée.
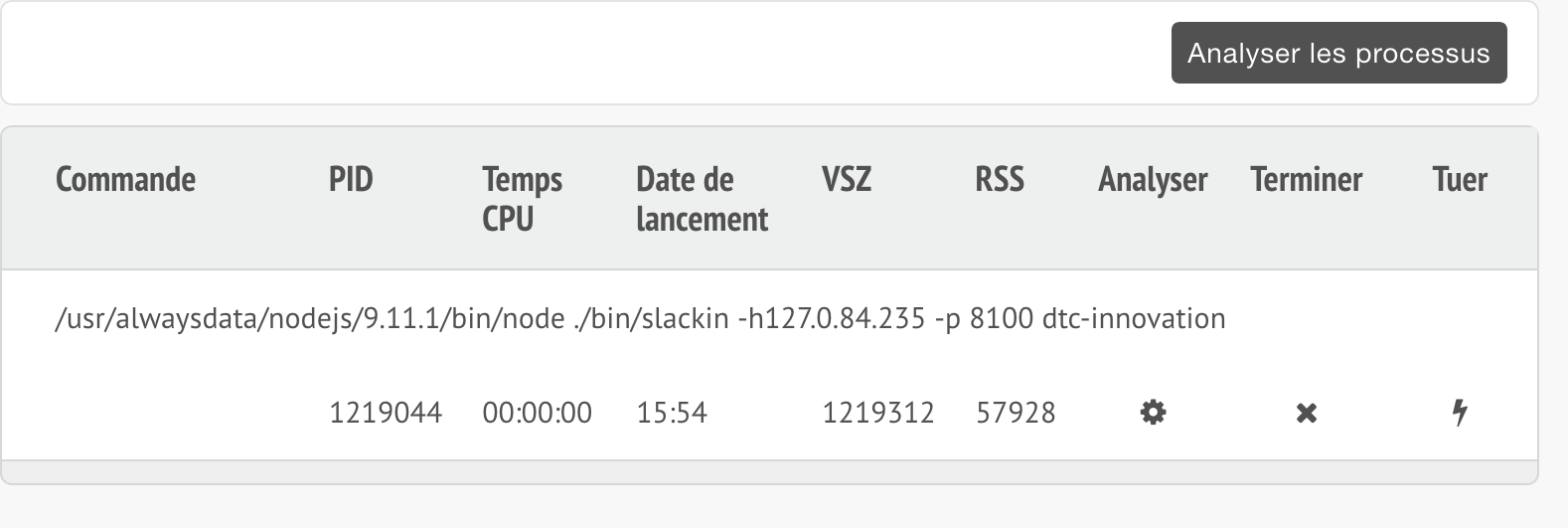
En cas de doute, un bouton Redémarrer est affiché à côté du bouton Modifier dans la liste des sites. L’application sera alors interrompue et relancée. Cette opération est nécessaire pour que l’application prenne en compte les changements après une mise à jour ou un plantage.
|
💬
|
Configuration Une application Node par site
Alwaysdata nous permet d’associer un seul processus à un seul site. Pour rendre une application Node accessible sur Internet, il faudra créer un nouveau site et lui associer un autre nom de domaine, ou un sous-domaine. |
|
💡
|
Aide Forum d’entraide
L’équipe et la communauté alwaysdata (forum.alwaysdata.com) sont sympathiques et à l’écoute. C’est un endroit idéal pour chercher des informations et poser des questions pour mieux comprendre ce qui empêche votre application de fonctionner sur leurs services. |
8.3. Serveur virtualisé, dédié ou cloud
La location d’un serveur dédié revient à payer pour un ordinateur complet, son entretien physique et son placement dans un datacenter – un immense parc à ordinateurs connecté à un réseau haute capacité.
Les Virtual Private Servers (VPS) sont des machines virtuelles (Virtual Machine, VM) : les ressources d’un serveur dédié sont réparties en plusieurs unités indépendantes les unes des autres, les VM.
Les offres cloud sont une version “élastique” des VM : la puissance de calcul, la bande passante et la mémoire allouées sont ajustables sans avoir à changer de machine, sans avoir à tout réinstaller. Ces ressources sont considérées comme étant “à la demande” : elles s’obtiennent en quelques secondes et peuvent être mises en pause, réduites, augmentées ou supprimées à tout moment.
Leur modèle de facturation s’adapte à la souplesse d’allocation des ressources :
-
au mois : VPS, serveur virtualisé, serveur dédié ;
-
à l’heure : serveur cloud ;
-
à la (milli)seconde : fonction événementielle.
Les modes de déploiement adaptés sont Git pour obtenir le code, l'orchestration d’applications avec Docker en combinaison avec des recettes de déploiement et l'intégration continue.
L’offre de serveurs virtualisés et dédiés (VPS, VM) est adaptée à des besoins constants et pour héberger plusieurs applications sur une même machine – à coût constant.
| Service | Déploiement | Add-ons | Tarif horaire | Tarif mensuel |
|---|---|---|---|---|
SSH |
✔ |
- |
4 €/VM |
|
SSH, CLI, API |
✔ |
- |
14,5 €/serveur |
|
SSH, API |
✔ |
- |
149 €/VM |
L’offre cloud est plus intéressante si vos besoins sont singulièrement fluctuants – par exemple lorsqu’il y a besoin de doubler la CPU pendant deux heures, à heure fixe ou en fonction de la charge, mais aussi quand il s’agit d’ajouter dix serveurs d’un coup pour traiter un calcul gourmand.
| Service | Déploiement | Add-ons | Tarif horaire | Tarif mensuel |
|---|---|---|---|---|
CLI, SSH, API |
✘ |
0,004 € |
2,30 €/VM |
|
CLI, Git, API, Web |
✔ |
0,0075 $ |
5,00 $/VM |
|
CLI, Git |
✘ |
0,0081 € |
6,00 €/VM |
|
SSH, API, Web |
✔ |
0,062 € |
26,00 €/VM |
|
CLI, API |
✘ |
0,007 $ |
5,00 $/VM |
|
CLI, API, SSH, Web |
✔ |
0,0132 $ |
9,67 $/VM |
|
💡
|
Avancé HashiCorp Terraform
Le logiciel Terraform (terraform.io/) a pour intention de documenter une infrastructure (serveurs, DNS, stockage, etc.) sous forme d’un fichier de configuration – versionnable avec Git. C’est un outil idéal pour automatiser le déploiement d’une infrastructure de zéro, mais aussi pour la faire évoluer d’une version à une autre. Nous pouvons ainsi créer une architecture combinant plusieurs fournisseurs sans gérer la complexité et la non-interopérabilité de leurs API. |
8.4. Fonction événementielle (Serverless, Lambda)
La fonction événementielle est l’évolution ultime des offres cloud. Au lieu de payer une machine ou une VM à l’heure, nous payons pour exécuter du code à la milliseconde. Ce code se déclenche en réaction à un événement se produisant ailleurs sur l’infrastructure : une requête HTTP entrante, un nouveau fichier ou encore un appel de l’API de l’hébergeur.
C’est le moyen le plus économique pour exécuter du code à tout instant sans payer le temps d’inactivité d’une machine. On pourrait comparer ce modèle à celui de la téléphonie mobile lorsqu’on a à choisir entre un forfait (coût fixe même si on ne consomme pas tout) et un paiement à la carte (coût dépendant de la consommation).
Les applications destinées à être exécutées comme fonctions événementielles
ont une architecture un peu différente.
Au lieu de démarrer un serveur web basé sur le
module http, nous exposons
une fonction qui retourne un résultat de manière asynchrone :
'use strict';
const getPokemonName = require('pokemon-random-name');
module.exports = (context, send) => { // (1)
return send(null, getPokemonName());
};-
Le paramètre
contextcontient des informations à propos de la requête entrante – paramètres, corps du message, etc.
Ce code est très similaire à ce que nous pourrions écrire lors de l’événement
server.on('request') du module http.
Voyons cela en contexte dans l’interface web du service Webtask (webtask.io/make) :
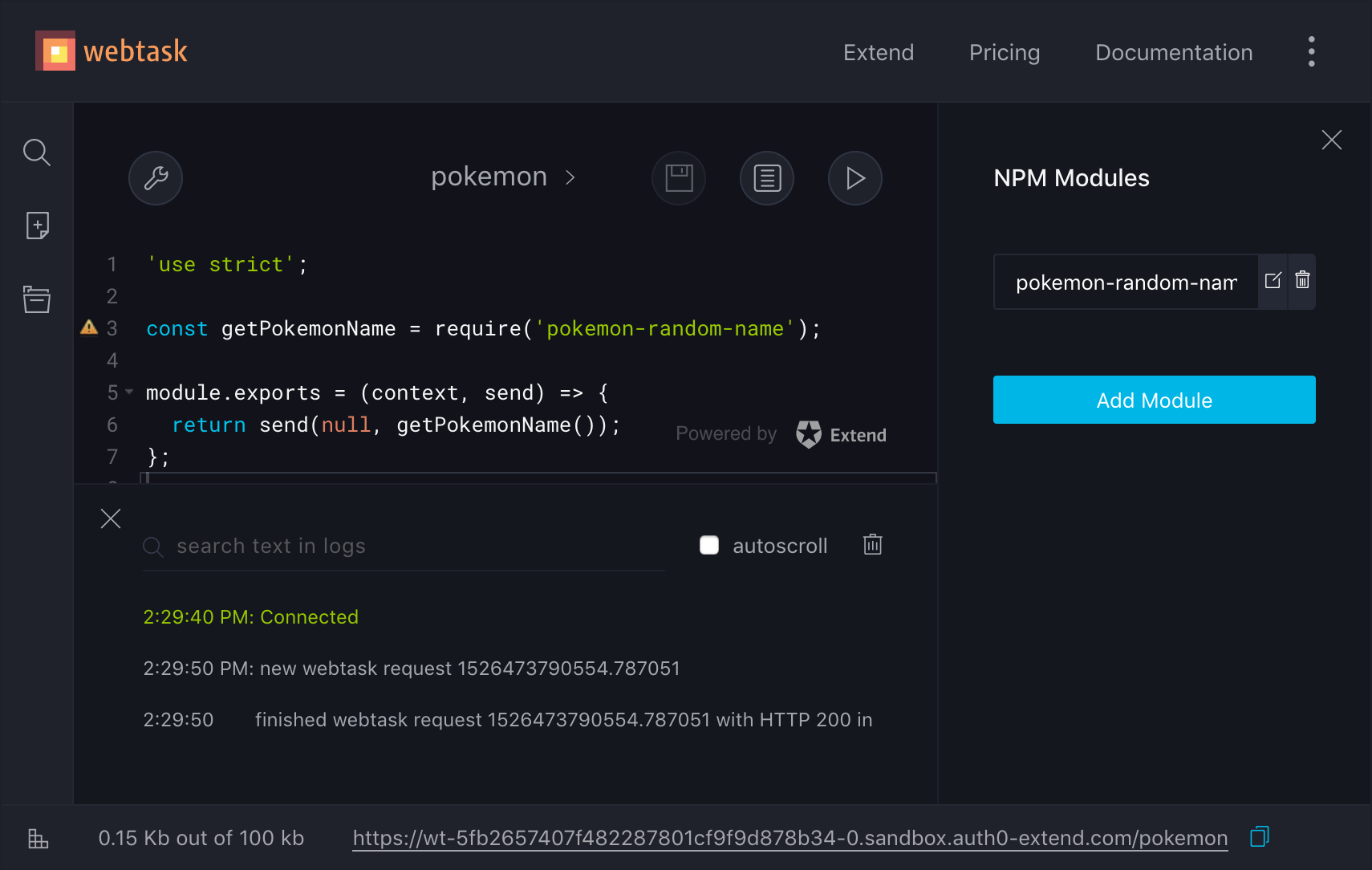
Un nom de Pokémon est affiché lorsque nous accédons à l’URL indiquée en bas de l’écran.
| Service | Déploiement | Gratuité | Tarif des requêtes |
|---|---|---|---|
Web, CLI, API |
1 M requêtes/mois |
0,2 $/million |
|
Web, GitHub, CLI, API |
1 requête/seconde |
sur devis |
|
Web, GitHub, CLI, API |
2 M equêtes/mois |
0,4 $/million |
|
zeit.co/now + |
CLI, API |
3 apps |
15 $/mois |
Chaque fournisseur de fonction événementielle a sa propre vision des paramètres qui nous sont donnés, mais leurs fonctionnements restent très proches.
Je trouve que Webtask est le service avec la plus faible courbe d’apprentissage. Son interface y est pour beaucoup.
Le service now est intéressant à plus d’un titre.
Il déploie un outil en ligne de commande minimaliste,
y compris des conteneurs Docker.
Il se transforme en fonction événementielle avec l’aide du
module npm
micro (npmjs.com/micro).
Le service Amazon Lambda représente une marche d’apprentissage un peu plus importante. C’est un service important de par l’outillage et la documentation disponibles à son sujet. Le service est complet, surtout une fois couplé avec le service Amazon API Gateway.
|
💡
|
Avancé Amazon API Gateway
Les Lambda d’Amazon ne sont pas accessibles depuis Internet par défaut. Pour ce faire, il faut les relier au service et associer chaque route à une Lambda. Le service se charge de transformer le résultat – une chaîne de caractères, un tableau ou un objet ECMAScript – en une réponse HTTP. |
|
💬
|
Définition Serverless
Ce type d’infrastructure a été nommé serverless suite à une organisation du marché pour proposer des alternatives aux Lambda d’Amazon. Quand on entend le mot serverless – littéralement, sans serveur – il faut comprendre “sans serveur à gérer soi-même”. L’hébergeur dispose quand même de machines pour exécuter le code. Leurs ressources sont mutualisées au maximum. |
9. Améliorer la portabilité applicative
Le fonctionnement d’une application Node risque d’être affecté suite à son déploiement en ligne.
Cette section a pour but de mettre en lumière des points importants qui contribuent à la portabilité de l’application – c’est-à-dire son bon fonctionnement une fois installée autre part que sur un ordinateur de développement, indépendamment du service d’hébergement retenu.
9.1. Utiliser la bonne version de Node
Les plates-formes de services et certains services d’intégration continue utilisent deux mécanismes pour déterminer notre préférence quant à la version de Node à utiliser :
-
le fichier
.nvmrc; -
la valeur
engines.nodedu fichierpackage.json.
Dans les deux cas, cela revient à préciser la version de Node pour chacun de nos projets.
|
💡
|
Conseil Une version de Node par application
Je trouve qu’il est plus facile d’adapter la version de Node au cas par cas au lieu de m’imposer une seule version pour tout le code que j’écris. C’est très utile quand je reprends le code après plusieurs mois d’inactivité. |
Si vous avez décidé d’utiliser nvm
(chapitre 2) ou si vous utilisez un service
compatible, sachez que cet outil sait s’adapter à la version
de Node précisée dans le fichier .nvmrc.
Un fichier .nvmrc ressemble à ceci :
v10
Avec cette valeur, cela revient au même de faire
nvm install v10 et nvm install.
La commande nvm use lit également la version contenue dans .nvmrc
et bascule automatiquement vers celle-ci :
nvm install nvm use node --version
Les plates-formes de services qui ne se basent pas sur nvm
regardent en général dans le fichier package.json :
{
"name": "my-app",
"engines": {
"node": "10.x.x"
}
}Cette notation signifie “la version la plus récente de Node v10”.
Enfin, la dernière version de Node est utilisée si cette information ne peut pas être déterminée avec les deux mécanismes précédemment cités.
9.2. L’application tourne mais elle est injoignable
Il est nécessaire de renseigner un port lorsqu’on démarre un serveur
avec le module http
(cf. chapitre 4).
Pourtant, nous allons faire face à un “problème” si le code suivant est déployé
sur une plate-forme de services.
'use strict';
const server = require('http').createServer();
server.listen(8000, () => console.log('localhost:8000'));Le déploiement est considéré comme réussi, mais l’application est injoignable. En effet, les plates-formes de services choisissent ce port pour nous et l’associent à l’URL de notre application – monapplication.heroku.com par exemple.
Le port est exposé au travers d’une
variable d’environnement
(chapitre 4).
Par convention, c’est la variable PORT qui est utilisée.
Nous n’avons qu’à adapter le script précédent de cette manière :
'use strict';
const server = require('http').createServer();
const {PORT=8000} = process.env; // (1)
server.listen(PORT, () => console.log(`localhost:${PORT}`));-
Extrait la valeur de la variable d’environnement
process.env.PORT.
La variable d’environnement PORT sera utilisée si elle existe et, sinon,
le port 8000 sera la valeur par défaut :
node server-port-dynamic.js PORT=4000 node server-port-dynamic.js
-
Affiche
localhost:8000. -
Affiche
localhost:4000.
C’est un premier pas pour s’affranchir des éléments de configuration écrits en dur.
9.3. S’affranchir des chemins et configurations écrits “en dur”
La configuration du port de l’application n’est pas le seul élément contextuel à changer entre notre ordinateur et un autre – que ce soit celui d’une personne contribuant au projet, au service d’intégration continue ou au serveur d’hébergement.
Les variables d’environnement sont à privilégier pour configurer nos applications avec souplesse. Elles s’appliquent aux :
-
URL d’accès aux bases de données, à des API distantes ;
-
clés d’API pour utiliser des services externes ;
-
réglages influençant le comportement de l’application ;
-
chemins d’accès vers des fichiers ou répertoires (stockage, cache) ;
-
environnements d’exécution (développement, test, production).
L’accès à une base de données est un parfait exemple. Les nom d’utilisateur, mot de passe et adresse du serveur peuvent d’ailleurs se combiner en une seule variable composée sous forme d’URL.
Par exemple, si vous avez connaissance des identifiants et de l’adresse d’une base de données MySQL ou MariaDB, composez l’URL de configuration comme suit :
MYSQL_URL=mysql://user:password@server/database \ node sql-connect.js
'use strict';
const mysql = require('mysql2/promise');
const url = process.env.MYSQL_URL;
mysql.createConnection(url).then((connection) => { // (1)
console.log('Connexion réussie :-)'); // (2)
connection.end(); // (3)
});-
Connexion à la base de données en utilisant la variable d’environnement
MYSQL_URL. -
Affiche
Connexion réussie :-)en cas de succès de connexion à la base de données. -
Clôture de la connexion – sinon, le script ne se terminerait pas sans avoir recours à Ctrl+C.
Le script d’exemple devrait avoir affiché la liste des tables contenues dans cette base de données ou un message d’erreur le cas échéant.
La documentation du module npm
mysql2 (npmjs.com/mysql2) détaille les différentes fonctions
utilisables pour interagir avec les bases de données compatibles.
|
💡
|
Raccourci Créer une base de données MySQL avec Docker
Docker est un outil utile pour créer une base de données en une ligne de commande et ce, sans avoir à installer MySQL sur notre ordinateur. docker run -ti --rm -e MYSQL_ROOT_PASSWORD=demo \ -p 3306:3306 mysql:5 Vous pourrez ainsi utiliser l’URL |
Certaines variables d’environnement sont tellement spécifiques à chaque usage qu’elles doivent être obligatoirement configurées – identifiants, URL de la base de données, etc. Je trouve pratique de proposer une valeur par défaut pour les autres – le port de l’application ou d’autres éléments plus “esthétiques”.
Enfin, j’ai aussi pris l’habitude de documenter les variables d’environnement
dans le fichier README.md à la racine de chaque projet.
Nous pouvons ainsi avoir une vue d’ensemble de la complexité de configuration
en un rapide coup d’œil – et cela nous évite de fouiller dans le code applicatif.
|
💡
|
Optimisation NODE_ENV=production
Certains modules NODE_ENV=production node app.js |
9.4. Faire persister les fichiers en dehors de notre application
Les fichiers écrits par notre application devraient être sauvegardés en dehors de son arborescence de fichiers.
Prenons cet exemple d’arborescence :
└── app ├── images └── uploads └── images
Les images sont stockées à deux endroits :
-
app/images: images statiques affichées par notre application web – on les versionne avec Git ; -
app/uploads/images: fichiers enregistrés sur le disque par l’intermédiaire de notre application – on ne les versionne pas avec Git.
Un inconvénient se présente à nous : tout est perdu si nous supprimons
le répertoire app pour réinstaller l’application de zéro.
Je conseille donc d'écrire tout nouveau fichier dans un répertoire indépendant.
L’arborescence se transformerait comme suit :
├── app
│ └── images
└── uploads
└── images
|
💡
|
Rappel Configurer le chemin avec une variable d’environnement
Le chemin d’accès devient flexible dès lors que nous le rendons configurable avec une variable d’environnement. UPLOAD_DIR=/uploads npm start |
Cette précaution s’avère encore plus utile dès lors que nous utilisons une plate-forme de services ou lorsque nous démarrons une nouvelle machine virtuelle. Chaque nouveau déploiement remet le système de fichiers à zéro.
Une solution complémentaire s’offre à nous lorsqu’il devient compliqué de partager un même stockage de fichiers entre plusieurs machines ou VM : c’est le stockage d’objets.
Le stockage d’objets est une solution de stockage élastique où la facturation est basée sur la quantité des données stockées et téléchargées. Nous accédons aux ressources stockées et à leur contenu avec des requêtes HTTP. Les fichiers sont ainsi disponibles à tout moment, sans limite et pour tous nos contextes applicatifs.
|
💬
|
Histoire Amazon S3
Amazon S3 est le premier service à avoir rendu populaire le stockage d’objets en 2006. C’était la première fois que nous pouvions stocker des fichiers de manière infinie, sans limitation de taille. Son interface d’accès est même devenue un standard de facto : il est utilisé par la plupart des concurrents afin de pouvoir passer d’un fournisseur à un autre sans avoir à changer grand-chose à ses applications. |
| Service | Emplacement(s) du stockage | Tarif mensuel |
|---|---|---|
Paris, Europe, Monde |
0,024 $/Go |
|
France |
0,01 €/Go |
|
Europe, Monde |
0,026 $/Go |
|
Flexible |
- |
9.5. Versionner les schémas de base de données
Le contenu et la structure d’une application risquent de changer selon qu’elle tourne sur notre ordinateur ou sur notre hébergement. Nous pourrions reporter les changements de structure à la main mais c’est source d’erreurs : difficile à reproduire et difficile à intégrer dans le processus de déploiement.
L’idéal est de synchroniser la structure de nos bases de données. Ou plutôt, l’idéal est de reproduire les changements de structure.
L’exemple suivant illustre la création d’un nouveau champ.
'use strict';
module.exports = {
up (database) { // (1)
return database.addColumn('fromages', 'aoc', { // (2)
type: 'boolean', // (3)
defaultValue: false,
});
}
}-
Fonction exécutée lors de la migration.
-
Nous ajoutons un champ
aocdans la tablefromages. -
Ce champ est de type booléen avec
falsecomme valeur par défaut.
Ce fichier représente une étape de migration. L’idée est de créer une nouvelle étape pour chaque changement de structure et de les jouer au prochain déploiement.
Cet exemple de migration se base sur le module npm db-migrate
(npmjs.com/db-migrate).
Il se connecte à la base de données de notre choix, charge la liste des
migrations et exécute celles qui n’ont pas encore été jouées.
Les migrations ne s’utilisent pas que pour changer la structure de la base de données, mais aussi pour la créer :
'use strict';
module.exports = {
up (database) {
return database.createTable('fromages', { // (1)
columns: {
id: { // (2)
type: 'int',
primaryKey: true,
autoIncrement: true
},
name: { // (3)
type: 'string'
}
}
});
}
}-
Création d’une nouvelle table
fromagesavec deux colonnes. -
La première colonne se nomme
id– elle est numérique et s’auto-incrémente à chaque nouvel enregistrement. -
La seconde colonne se nomme
name– c’est une chaîne de caractères.
Si nous mettons ces deux exemples bout à bout, nous sommes alors en mesure de créer une table puis d’y appliquer un changement en ajoutant une nouvelle colonne.
Ainsi, nous sommes en mesure de répliquer les changements de structures sur d’autres ordinateurs et reproduire l’évolution du schéma de la base de données en partant de zéro. Nous avons rejoué toutes les migrations sur notre outil d’intégration continue pour nous assurer de leur robustesse et revenir en arrière si nécessaire.
10. Démarrer automatiquement une application
Jusqu’à présent, nous avons démarré les scripts de cet ouvrage
avec l’exécutable node ou avec la commande npm start.
C’est un processus manuel qui nécessite de conserver un onglet ouvert
dans notre terminal pour maintenir l’application en fonctionnement.
Cette section explore des mécanismes pour détacher le processus du terminal et pour lancer l’application au démarrage ou redémarrage d’un ordinateur.
10.1. L’hébergeur s’en occupe à notre place
Les plates-formes de service automatisent le démarrage de
l’application.
Elles exécutent la commande npm start
dès que le déploiement est terminé.
C’est tout.
10.2. Avec un gestionnaire de processus
Un gestionnaire de processus a deux utilités :
-
détacher un processus de notre terminal – si on le ferme, l’application tourne toujours ;
-
gérer plusieurs processus par application – un frontal web et l’admin par exemple.
pm2 (pm2.keymetrics.io) est un gestionnaire de processus
disponible en tant que module npm
(npmjs.com/pm2).
Il fonctionne sous Linux, Windows et macOS.
La commande suivante démarre un script et le place aussitôt en tâche de fond :
pm2 start app.js
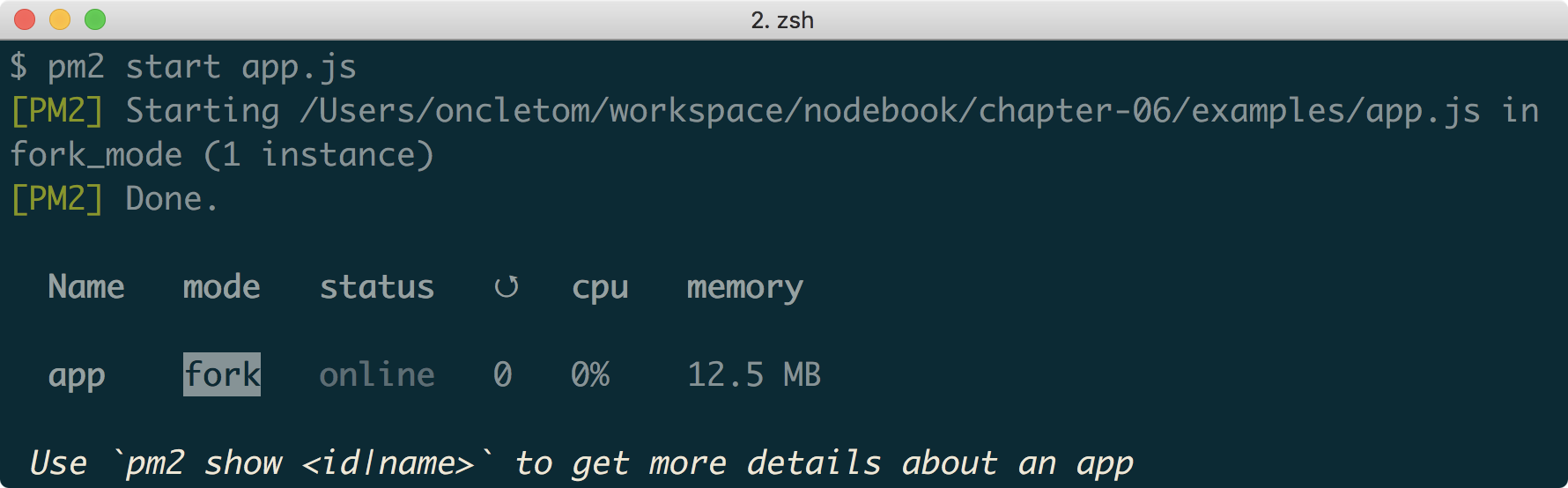
Cette même application s’arrête avec la commande pm2 stop et
se relance pour prendre en compte des changements de code avec pm2 restart.
Les gestionnaires de processus facilitent l’intégration d’une application en tant que service système (section suivante). C’est mon choix de prédilection pour ne pas avoir à apprendre un nouveau fichier de configuration.
La commande suivante nous guide dans la configuration de notre système d’exploitation :
pm2 startup
Celle-ci sauvegarde les applications démarrées avec le gestionnaire de processus. Elles seront restaurées au prochain redémarrage de l’ordinateur :
pm2 save
On peut aussi revenir en arrière et décider de désactiver le démarrage automatique de nos applications :
pm2 unstartup
|
💬
|
Windows Configurer pm2
La commande |
10.3. En créant un service système
Tous les systèmes d’exploitation ont un mécanisme pour démarrer des applications en fonction de certains critères : quand le réseau ou une connexion Internet est disponible, lorsqu’une session utilisateur s’est ouverte ou même quand un autre logiciel est actif.
Systemd, Upstart et launchd sont des gestionnaires de services système parmi d’autres. Ils se configurent avec des fichiers écrits dans des formats différents.
Voici un exemple de fichier de configuration pour systemd (doc.ubuntu-fr.org/systemd). C’est le gestionnaire de services des distributions Linux Ubuntu, Debian, Fedora et CentOS.
[Unit]
Description="Application Node.js"
After=NetworkManager.service // (1)
[Service]
Restart=on-failure // (2)
DefaultStartLimitBurst=5
StartLimitIntervalSec=120
User=nobody // (3)
Environment="NODE_ENV=production"
WorkingDirectory=/usr/local/node-app // (4)
ExecStart=/usr/bin/npm start // (5)-
L’application démarrera dès que l’interface réseau sera opérationnelle.
-
L’application sera relancée en cas de plantage – maximum 5 fois dans un délai de 120 secondes.
-
Le processus sera démarré au nom de l’utilisateur système
nobody. -
C’est comme si nous nous placions dans
/usr/local/node-appavant de lancer l’application – c’est la valeur qu’on retrouve avecprocess.cwd(). -
Commande à exécuter pour démarrer l’application.
Le service associé au fichier de configuration précédent peut être démarré manuellement comme suit :
Cf. /etc/systemd/nodebook.d/app.conf sudo systemctl start nodebook.service
Les commandes systemctl stop et systemctl restart
arrêtent et relancent un service.
Dans tous les cas, le service sera lancé automatiquement au prochain démarrage du système d’exploitation.
|
💡
|
Alternative Et pour Windows ?
Le gestionnaire de services Windows est compliqué à utiliser. Je recommande le module npm node-windows (npmjs.com/node-windows). |
10.4. Avec un serveur d’applications web
Un serveur d’applications web est un logiciel informatique qui a deux objectifs : être toujours disponible et répartir le trafic HTTP vers des fichiers et des applications web. C’est une sorte de parapluie optimisé et résistant qui se met au-devant de nos applications.
|
💬
|
Question Pourquoi utiliser un serveur d’applications ?
Les serveurs d’applications sont excellents pour gérer la charge des requêtes, se protéger de failles de sécurité HTTP et être performants dans le traitement des fichiers statiques. Leur capacité à redémarrer une application Node en cas de plantage ou de nouveau déploiement nous enlève une épine du pied. Certains ont même des facultés de répartition de charge (load balancing) : plusieurs instances de la même application tournent alors en parallèle – une par CPU. Le trafic est réparti vers l’instance qui a le plus de CPU disponible. |
Phusion Passenger (phusionpassenger.com/) est un serveur d’applications web open source, léger et performant. Il est compatible avec des applications Ruby, Node et Python. Il s’installe de manière autonome ou en complément des serveurs nginx (nginx.org) et Apache httpd (httpd.apache.org).
Regardons ensemble à quoi ressemble un fichier de configuration nginx minimaliste :
server {
listen 80 default_server;
server_name _;
root /var/www; // (1)
}-
Répertoire racine où nginx va chercher les fichiers.
Si nginx est lancé sur notre ordinateur avec ce fichier de configuration
et si le fichier image.jpg est placé dans le répertoire /var/www,
alors nous pourrons y accéder dans un navigateur web
sur localhost/image.jpg.
{kind=link}
Transformons maintenant ce fichier de configuration après avoir installé le module Phusion Passenger pour nginx (phusionpassenger.com/library/install/nginx/) :
server {
listen 80 default_server;
server_name _;
root /var/www;
passenger_enabled on; // (1)
passenger_app_type node; // (2)
passenger_app_root /var/apps/my-app; // (3)
passenger_startup_file app.js; // (4)
passenger_document_root /var/apps/my-app/public; // (5)
}-
Activation du module Phusion Passenger pour nginx.
-
Nous indiquons à Phusion Passenger qu’il s’agit d’une application Node.
-
L’application se trouve dans le répertoire
/var/apps/my-app. -
Le script à démarrer est
app.js– c’est-à-dire/var/apps/my-app/app.js. -
Emplacement où Phusion Passenger ira chercher les fichiers statiques.
Phusion Passenger démarre l’application Node pour nous. Il la maintient en vie en cas de plantage. Son comportement se configure finement à l’aide de directives dont la liste intégrale se trouve sur phusionpassenger.com/library/config/nginx/reference/.
11. À quoi penser après la mise en ligne ?
De la programmation au déploiement, nous sommes toujours en mesure de savoir quand quelque chose ne va pas : les erreurs se produisent sous nos yeux.
Les problèmes commencent à échapper à notre attention dès la mise en ligne. Regardons ensemble ce que nous pouvons faire pour intervenir au bon moment.
11.1. L’application a planté
Que se passe-t-il lorsqu’une application plante en plein milieu du week-end ? Rien. Nous n’en savons rien tant que nous n’allons pas sur l’application en question. L’action la plus simple à mettre en œuvre est de recevoir une alerte par courriel ou par SMS.
Pingdom (www.pingdom.com/free) répond exactement à ce besoin. Il est gratuit pour un site web et payant au-delà.
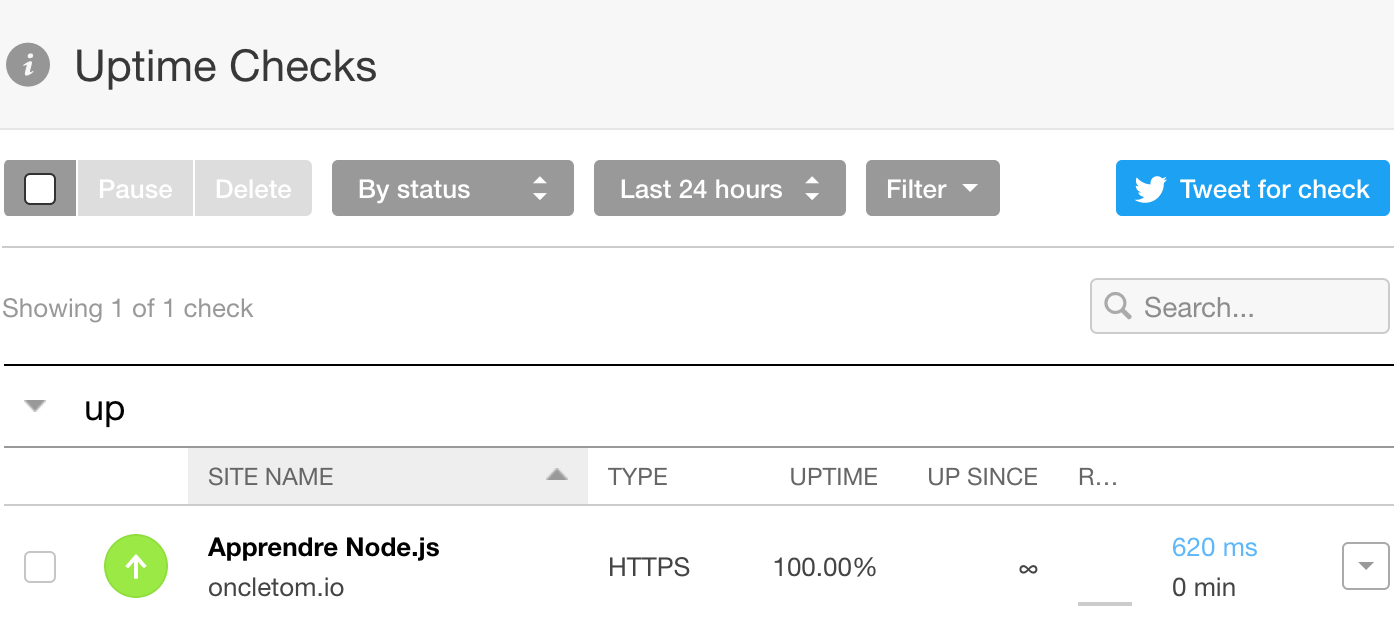
Uptime Robot (uptimerobot.com) est un service similaire. Il offre en plus un flux RSS d’alertes et une intégration avec Slack.
11.2. S’informer des erreurs applicatives
Lorsque nous prenons connaissance d’un plantage applicatif, comment déterminer ce qui l’a causé ?
S’il s’agit d’une application personnelle ou sans enjeu, nous pouvons nous contenter de reproduire le problème localement. Dans le cas d’une application professionnelle, nous aurons besoin de plus de précisions, rapidement.
Sentry (sentry.io) est un service en ligne qui s’intègre dans notre code comme une sonde. Une fois placée, la sonde transmet les erreurs vers la plate-forme Sentry. Cette dernière affiche les erreurs connues sous forme de tableau de bord – leur nature, combien de fois elles se répètent. Elle nous envoie également une notification par courriel avec une indication de sévérité, pour que nous puissions réagir plus ou moins rapidement.
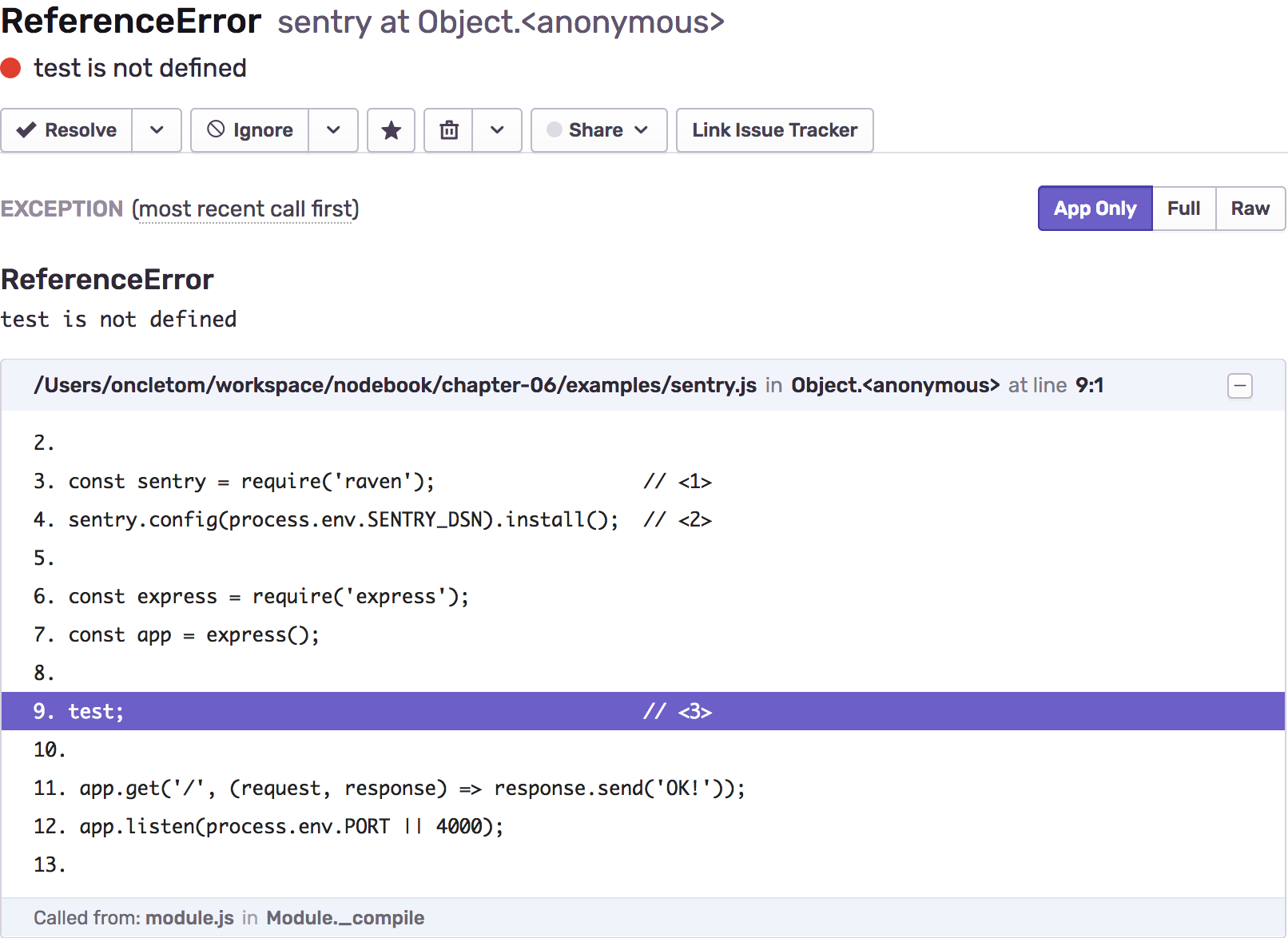
L’inclusion d’une sonde basique revient à insérer deux lignes dans notre code :
'use strict';
const sentry = require('raven'); // (1)
sentry.config(process.env.SENTRY_DSN).install(); // (2)
const express = require('express');
const app = express();
test; // (3)
app.get('/', (request, response) => response.send('OK!'));
app.listen(process.env.PORT || 4000);-
raven est le nom du module
npmédité par Sentry pour collecter les erreurs. -
Configuration du client Sentry – il collectera et enverra les erreurs auprès de la plate-forme.
-
Cette ligne est la source de notre erreur – la variable n’est pas définie.
Sentry nous communique une clé d’API pour chaque projet à instrumenter. Quand vous obtenez la vôtre, modifiez la ligne de commande suivante afin de provoquer l’erreur, de recevoir le courriel d’alerte et de la visualiser en détail sur le tableau de bord :
SENTRY_DSN=https://0c...@sentry.io/1201870 node sentry.js
|
💬
|
Documentation Configurer Sentry
Un guide complet (en anglais) documente comment aller plus loin dans l’utilisation de Sentry : |
Le service New Relic (newrelic.com/nodejs) est une alternative à Sentry. Il mesure également les performances et les sources de ralentissement. Il s’installe gratuitement et en quelques clics sur la plate-forme de services Heroku. Il devient payant à partir d’un certain volume de requêtes.
11.3. Notre version de Node fait l’objet d’une faille de sécurité
Certaines versions de Node sortent pour apporter de nouvelles fonctionnalités ou pour corriger des bogues. D’autres sont publiées pour corriger des failles de sécurité. Ces failles sont critiques pour nos applications.
Lorsqu’une faille est exploitée, la personne à l’origine de l’attaque peut ralentir, faire planter ou extraire des informations confidentielles de notre application. En cas de faille critique, l’attaquant·e risque aussi de gagner un accès à l’ordinateur et aux bases de données hébergeant l’application.
Solution : redéployer nos applications avec une version de Node plus récente.
Je vous encourage à recevoir des alertes par courriel ou en vous abonnant au fil RSS pour être prevenu·e au bon moment.
|
💬
|
Courriel
|
|
💬
|
Fil RSS
|
11.4. Un des modules npm fait l’objet d’une faille de sécurité
Les modules npm aussi risquent d’être affectés par des failles de sécurité.
Les conséquences de leur exploitation sont similaires à celles des failles de Node : les personnes à l’origine des attaques peuvent saturer le serveur et paralyser l’application. Elles sont aussi en mesure de subtiliser des informations confidentielles stockées en base de données ou saisies par les usagers.
Snyk (snyk.io) est un service de sécurité gratuit pour les projets open source. Il scanne les vulnérabilités de nos dépendances et sous-dépendances Il nous alerte sur la sévérité des failles décelées dans nos projets.
Ces failles sont classées en trois niveaux : dangereuses, modérées et superficielles. Mieux vaut mettre à jour les dépendances affectées par une faille dangereuse le plus rapidement possible.
Ce n’est pas grave si nous ne mettons pas à jour un vieux module npm.
En revanche, cela peut avoir un impact négatif si cette vieille version est
affectée par une faille.
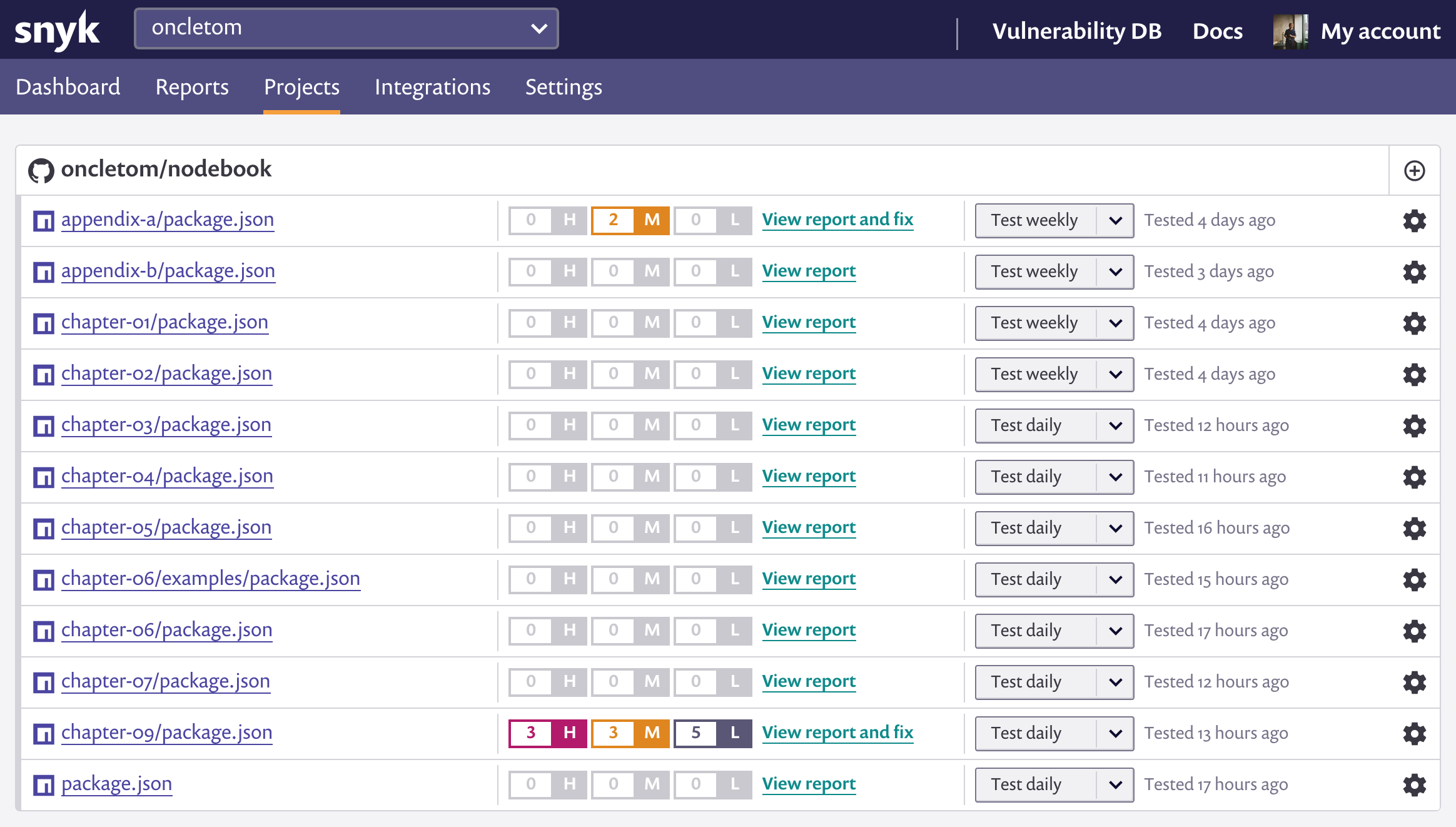
La capture d’écran suivante illustre une vulnérabilité décelée dans le
module npm restify dans sa version 4.
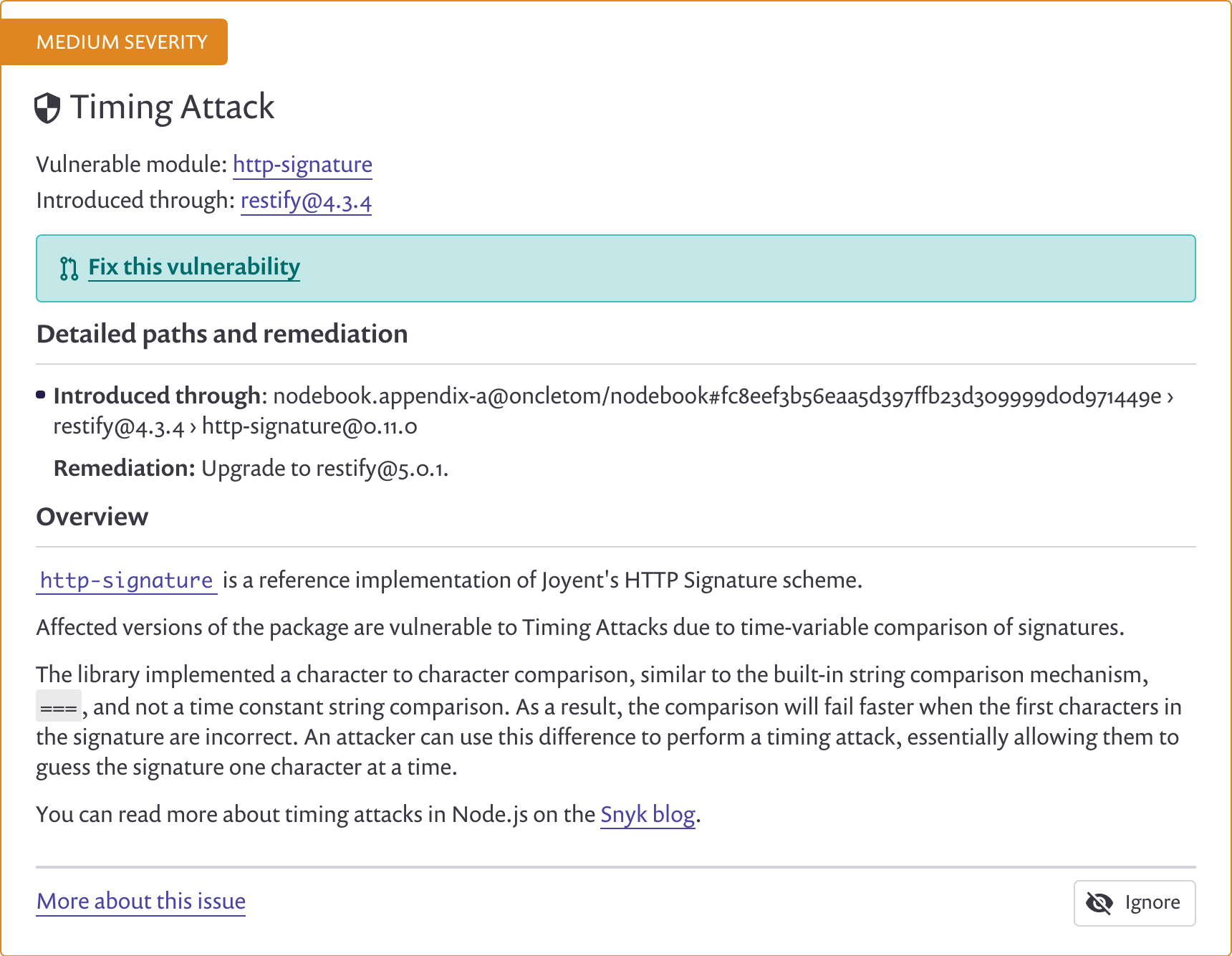
La correction du problème implique de passer à la version 5. Cette action nous demandera sûrement d’adapter notre code car nous changeons de version majeure. Ces migrations sont souvent documentées par les auteurs des modules.
|
💡
|
Pratique Intégrations npm, Heroku, etc.
Snyk s’intègre à d’autres services que GitHub : GitLab, Heroku, BitBucket, etc. Les applications au code source privé peuvent être vérifiées gratuitement avec l’API de Snyk ou son application en ligne de commandes. |
|
💬
|
Base de données
|
|
💬
|
Fil RSS
|
Nous avons parlé de la commande npm audit dans
le chapitre 5.
Elle dispose d’une option pour mettre à jour automatiquement
les dépendances dangereuses : npm audit fix.
npm audit fix fixed 20 of 21 vulnerabilities in 1867 scanned packages 1 vulnerability required manual review and could not be updated
Rester à l’écoute des vulnérabilités en combinaison de l’utilisation
de Snyk ou de npm audit fix suffit à prendre des mesures de correction
efficaces sans avoir à trop s’y connaître.
La lecture des rapports de vulnérabilité est un bon moyen de comprendre comment ces exploits fonctionnent et comment penser nos applications pour éviter d’exposer une surface d’attaque minimale.
12. Conclusion
Nous avons désormais toutes les clés pour partager notre code et le résultat de son exécution de manière publique.
Nous avons appris à choisir un hébergement et un mode de déploiement adapté à notre temps disponible ainsi qu’à nos envies. Nous sommes en mesure d’aller vite ou de prendre le temps de configurer une machine pour des besoins très précis.
La configuration d’une application avec des variables d’environnement est une des clés pour automatiser le déploiement.
L'automatisation du démarrage d’une application demande d’investir du temps pour être à l’aise. Ce temps est utile car le principe s’applique à d’autres langages et ouvre la porte de la maîtrise de l’hébergement applicatif, quand les plates-formes de service commencent à nous coûter trop cher.